

Введение в команды Pig
Apache Pig - инструмент / платформа, которая используется для анализа больших наборов данных и выполнения длинных серий операций с данными. Свинья используется с Hadoop. Все сценарии PIG внутренне преобразуются в задачи сокращения карты, а затем выполняются. Он может обрабатывать структурированные, полуструктурированные и неструктурированные данные. Свинья хранит, его результат в HDFS. В этой статье мы узнаем больше типов команд Pig.
Вот некоторые характеристики свиньи:
- Самооптимизация: Свинья может оптимизировать выполнение заданий, у пользователя есть свобода сосредоточиться на семантике.
- Простота программирования: Pig предоставляет язык / диалект высокого уровня, известный как Pig Latin, который легко писать. Pig Latin предоставляет множество операторов, которые программист может использовать для обработки данных. Программист имеет возможность писать свои собственные функции.
- Расширяемость: Pig облегчает создание пользовательской функции, которая называется UDF (пользовательские функции), которая позволяет программистам быстро и легко выполнять любые требования к обработке. Скрипт Pig работает на оболочке, известной как хрюканье.
Почему команды свиней?
Программисты, которые плохо разбираются в Java, обычно испытывают трудности при написании программ на Hadoop, то есть при написании задач сокращения карт. Для них Pig Latin, который очень похож на язык SQL, является благом. Подход с несколькими запросами уменьшает длину кода.
Так что в целом это лаконичный и эффективный способ программирования. Команды Pig могут вызывать код на многих языках, таких как JRuby, Jython и Java.
Архитектура Команды Свиньи
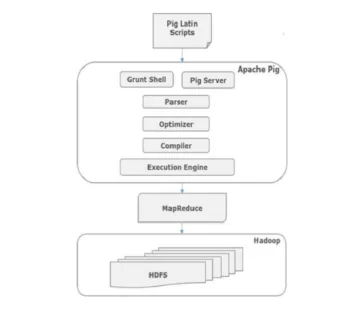
Все скрипты, написанные на Pig-Latin через grunt shell, отправляются в синтаксический анализатор для проверки синтаксиса, а также выполняются другие разные проверки. Выход синтаксического анализатора - DAG. Затем эта группа DAG передается оптимизатору, который затем выполняет логическую оптимизацию, такую как проекция, и отправляет ее вниз. Затем компилятор выполняет логический план заданий MapReduce. Наконец, эти задания MapReduce передаются в Hadoop в отсортированном порядке. Эти задания выполняются и дают желаемые результаты.
Модель данных Pig-Latin полностью вложена, и она допускает сложные типы данных, такие как map и tuple.
Любое отдельное значение языка Pig Latin (независимо от типа данных) известно как Atom.
Основные команды Pig
Давайте посмотрим на некоторые команды Basic Pig, которые приведены ниже:
1. Fs: это будет список всех файлов в HDFS
grunt> fs –ls
2. Очистить: это очистит интерактивную оболочку Grunt.
хрюкать> ясно
3. История:
Эта команда показывает команды, выполненные до сих пор.
ворчать> история
4. Чтение данных. Предполагается, что данные находятся в HDFS, и нам нужно прочитать данные в Pig.
grunt> College_students = LOAD 'hdfs: // localhost: 9000 / pig_data / College_data.txt'
ИСПОЛЬЗОВАНИЕ PigStorage (', ')
как (id: int, имя: chararray, фамилия: chararray, телефон: chararray,
город: chararray);
PigStorage () - это функция, которая загружает и сохраняет данные в виде структурированных текстовых файлов.
5. Хранение данных: Оператор хранилища используется для хранения обработанных / загруженных данных.
grunt> STORE College_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Здесь «/ pig_Output /» - это каталог, в котором необходимо сохранить отношение.
6. Оператор дампа: эта команда используется для отображения результатов на экране. Обычно это помогает при отладке.
grunt> Дамп College_students;
7. Опишите оператор: он помогает программисту просматривать схему отношения.
ворчать> описывать College_students;
8. Объясните: эта команда помогает просмотреть логический, физический и план сокращения планов.
ворчать, > объяснять колледж
9. Оператор Illustrate: дает пошаговое выполнение операторов в командах Pig.
ворчать> проиллюстрировать College_students;
Промежуточные команды Pig
1. Группа: Эта команда Pig работает для группировки данных с одним и тем же ключом.
grunt> group_data = GROUP College_students по имени;
2. COGROUP: работает аналогично групповому оператору. Основное различие между оператором Group и Cogroup заключается в том, что оператор group обычно используется с одним отношением, а cogroup - с несколькими отношениями.
3. Присоединиться: используется для объединения двух или более отношений.
Пример: для выполнения самосоединения, скажем, отношение «клиент» загружается из команд HDFS tp pig в двух отношениях «клиенты1» и «клиенты2».
grunt> Customers3 = ПРИСОЕДИНИТЬМЯ customer1 BY id, Customers2 BY id;
Присоединение может быть самостоятельным, внутренним, внешним.
4. Cross: эта команда pig вычисляет перекрестное произведение двух или более отношений.
grunt> cross_data = CROSS клиенты, заказы;
5. Союз: объединяет два отношения. Условием объединения является то, что столбцы и домены отношения должны быть идентичными.
grunt> student = UNION student1, student2;
Расширенные команды свиней
Давайте посмотрим на некоторые из продвинутых команд Pig, которые приведены ниже:
1. Фильтр: помогает отфильтровать кортежи вне зависимости от определенных условий.
filter_data = FILTER College_students BY city == 'Ченнай';
2. Отличительный: Это помогает в удалении избыточных кортежей из отношения.
grunt> Different_data = DISTINCT College_students;
Эта фильтрация создаст новое имя отношения «Different_data»
3. Foreach: это помогает в создании преобразования данных на основе данных столбца.
grunt> foreach_data = FOREACH student_details GENERATE id, возраст, город;
Он получит значения id, возраста и города каждого учащегося из отношения student_details и, следовательно, сохранит его в другом отношении с именем foreach_data.
4. Упорядочить по: эта команда отображает результат в отсортированном порядке на основе одного или нескольких полей.
grunt> order_by_data = ORDER College_students BY возраст DESC;
Это позволит отсортировать отношение «College_students» в порядке убывания по возрасту.
5. Лимит: эта команда ограничена нет. кортежей из отношения.
grunt> limit_data = LIMIT student_details 4;
Советы и приемы
Ниже приведены различные советы и хитрости команд Pig: -
1. Включите сжатие на вашем входе и выходе:
установить input.compression.enabled true;
установить output.compression.enabled true;
Вышеупомянутые строки кода должны находиться в начале скрипта, чтобы команды Pig могли читать сжатые файлы или генерировать сжатые файлы в качестве вывода.
2. Присоединяйтесь к нескольким отношениям:
Для выполнения левого соединения, скажем, трех отношений (input1, input2, input3) необходимо выбрать SQL. Это связано с тем, что Pig не поддерживает внешнее соединение для более чем двух таблиц.
Скорее вы выполняете оставленный, чтобы присоединиться в двух шагах как:
data1 = JOIN input1 BY ключ ВЛЕВО, input2 BY ключ;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Это означает два задания по уменьшению карты.
Для более эффективного выполнения вышеуказанной задачи можно выбрать «Cogroup». Cogroup может вступать в несколько отношений. Cogroup по умолчанию выполняет внешнее соединение.
Вывод
Свинья - это процедурный язык, обычно используемый учеными-данными для выполнения специальной обработки и быстрого прототипирования. Это отличный ETL и инструмент для обработки больших данных. Скриптовые сценарии могут вызываться другими языками и наоборот. Следовательно, команды Pig могут использоваться для создания больших и сложных приложений.
Рекомендуемые статьи
Это было руководство к командам Свиньи. Здесь мы обсудили как основные, так и расширенные команды Pig и некоторые непосредственные команды Pig. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Adobe Photoshop Commands
- Табличные команды
- Шпаргалка SQL (команды, бесплатные советы и хитрости)
- Команды VBA - последние штрихи
- Различные операции, связанные с кортежами