
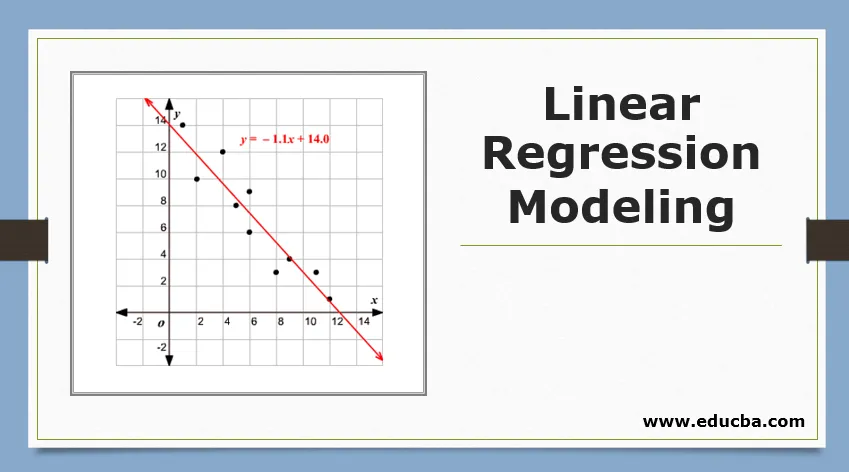
Обзор моделирования линейной регрессии
Когда вы начнете изучать алгоритмы машинного обучения, вы начнете узнавать о различных способах алгоритмов ML, таких как контролируемое, неконтролируемое, полууправляемое и обучающее обучение. В этой статье мы будем иметь дело с контролируемым обучением и одним из основных, но мощных алгоритмов: линейной регрессией.

Следовательно, контролируемое обучение - это обучение, при котором мы обучаем машину понимать взаимосвязь между входными и выходными значениями, представленными в наборе обучающих данных, а затем используем ту же модель для прогнозирования выходных значений для набора проверочных данных. Таким образом, в основном, если у нас есть выходные данные или метки, уже предоставленные в нашем наборе обучающих данных, и мы уверены, что предоставленные выходные данные имеют смысл, соответствующий входным данным, тогда мы используем контролируемое обучение. Контролируемые алгоритмы обучения подразделяются на регрессию и классификацию.
Алгоритмы регрессии используются, когда вы замечаете, что выходные данные являются непрерывной переменной, тогда как алгоритмы классификации используются, когда выходные данные делятся на такие разделы, как Пройдено / Не выполнено, Хорошее / Среднее / Плохое и т. Д. У нас есть различные алгоритмы для выполнения регрессии или классификации действия с Алгоритмом линейной регрессии, являющимся основным алгоритмом в регрессии.
Переходя к этой регрессии, прежде чем приступить к алгоритму, позвольте мне установить базу для вас. В школе я надеюсь, что вы помните концепцию уравнения линии. Позвольте мне кратко рассказать об этом. Вам дали две точки на плоскости XY, т.е., скажем, (x1, y1) и (x2, y2), где y1 - это выход x1, а y2 - выход x2, тогда линейное уравнение, которое проходит через точки: (y- y1) = m (x-x1) где m - наклон линии. Теперь, после нахождения линейного уравнения, если вам дается точка, скажем (x3, y3), вы сможете легко предсказать, находится ли точка на линии или на расстоянии точки от линии. Это была основная регрессия, которую я совершил в школе, даже не осознавая, что это будет иметь такое большое значение в машинном обучении. Обычно мы пытаемся определить линию или кривую уравнения, которые могли бы соответствовать входным и выходным данным набора данных поезда, а затем использовать это же уравнение для прогнозирования выходного значения набора тестовых данных. Это приведет к непрерывному желаемому значению.
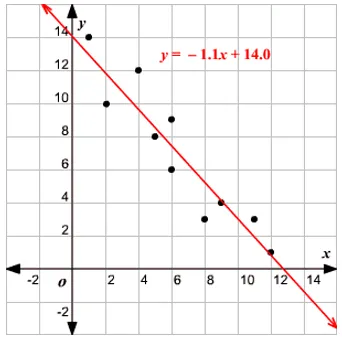
Определение линейной регрессии
Линейная регрессия на самом деле существует очень давно (около 200 лет). Это линейная модель, т.е. она предполагает линейную зависимость между входными переменными (x) и одной выходной переменной (y). Здесь y вычисляется по линейной комбинации входных переменных.
У нас есть два типа линейной регрессии
Простая линейная регрессия
Когда есть одна входная переменная, то есть уравнение строки равно
рассматривается как y = mx + c, то это простая линейная регрессия.
Множественная линейная регрессия
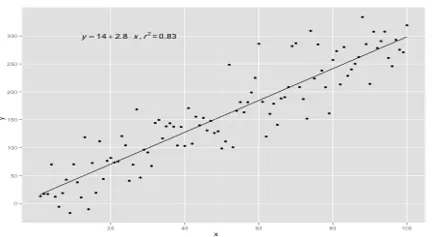
Когда имеется несколько входных переменных, т.е. линейное уравнение рассматривается как y = ax 1 + bx 2 +… nx n, то это множественная линейная регрессия. Различные методы используются для подготовки или обучения уравнения регрессии на основе данных, и наиболее распространенный из них называется Обыкновенные наименьшие квадраты. Модель, построенная с использованием упомянутого метода, называется линейной регрессией наименьших квадратов или просто регрессией наименьших квадратов. Модель используется, когда входные значения и определяемое выходное значение являются числовыми значениями. Когда есть только один вход и один выход, тогда сформированное уравнение является линейным уравнением, т.е.
y = B0x+B1
где коэффициенты линии должны быть определены с использованием статистических методов.
Модели простой линейной регрессии очень редко встречаются в ML, потому что, как правило, мы будем иметь различные входные факторы для определения результата. Когда имеется несколько входных значений и одно выходное значение, тогда образуется уравнение плоскости или гиперплоскости.
y = ax 1 +bx 2 +…nx n
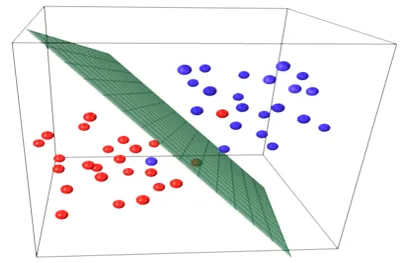
Основная идея регрессионной модели заключается в получении линейного уравнения, которое наилучшим образом соответствует данным. Лучше всего подходит линия, в которой общая ошибка прогноза для всех точек данных считается как можно меньшей. Ошибка - это расстояние между точкой на плоскости и линией регрессии.
пример
Начнем с примера простой линейной регрессии.

Соотношение между ростом и весом человека прямо пропорционально. Было проведено исследование на добровольцах, чтобы определить рост и идеальный вес человека, и значения были записаны. Это будет считаться нашим набором обучающих данных. Используя обучающие данные, вычисляется уравнение линии регрессии, которое даст минимальную ошибку. Это линейное уравнение затем используется для прогнозирования новых данных. То есть, если мы даем рост человека, то соответствующий вес должен быть предсказан разработанной нами моделью с минимальной или нулевой ошибкой.
Y(pred) = b0 + b1*x
Значения b0 и b1 должны быть выбраны так, чтобы они минимизировали ошибку. Если в качестве метрики для оценки модели принимается сумма квадратов ошибок, то цель состоит в том, чтобы получить линию, которая лучше всего уменьшает ошибку.
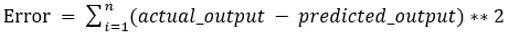
Мы возводим в квадрат ошибку, чтобы положительные и отрицательные значения не компенсировали друг друга. Для модели с одним предиктором:
Расчет перехвата (b0) в уравнении линии выполняется путем:
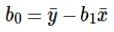
Расчет коэффициента для входного значения x осуществляется путем:
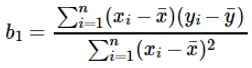
Понимание коэффициента b 1 :
- Если b 1 > 0, то x (вход) и y (выход) прямо пропорциональны. То есть увеличение x будет увеличивать y, например, рост увеличивается, вес увеличивается.
- Если b 1 <0, то x (предиктор) и y (цель) обратно пропорциональны. То есть увеличение x будет уменьшать y, например, при увеличении скорости транспортного средства, время уменьшается.
Понимание коэффициента b 0 :
- B 0 принимает остаточное значение для модели и гарантирует, что прогноз не смещен. Если у нас нет члена B 0, тогда линейное уравнение (y = B 1 x) вынуждено проходить через начало координат, то есть входные и выходные значения, введенные в модель, приводят к 0. Но это никогда не будет иметь место, если мы имеем 0 на входе, тогда B 0 будет средним из всех прогнозируемых значений, когда x = 0. Установка всех значений предикторов равными 0 в случае x = 0 приведет к потере данных и часто невозможна.
Помимо коэффициентов, упомянутых выше, эта модель также может быть рассчитана с использованием нормальных уравнений. Я буду обсуждать дальнейшее использование нормальных уравнений и проектирование простой / мультилинейной регрессионной модели в моей следующей статье.
Рекомендуемые статьи
Это руководство по моделированию линейной регрессии. Здесь мы обсудим определение, типы линейной регрессии, которая включает в себя простую и множественную линейную регрессию, а также некоторые примеры. Вы также можете посмотреть следующие статьи, чтобы узнать больше:
- Линейная регрессия в R
- Линейная регрессия в Excel
- Прогнозирующее моделирование
- Как создать GLM в R?
- Сравнение линейной регрессии и логистической регрессии