

Глубокое Изучение Интервью Вопросы И Ответы
Сегодня Deep Learning считается одной из самых быстрорастущих технологий с огромной способностью разрабатывать приложения, которые некоторое время назад считались сложными. Распознавание речи, распознавание изображений, поиск шаблонов в наборе данных, классификация объектов на фотографиях, генерация текста персонажей, автомобили с автоматическим вождением и многое другое - это всего лишь несколько примеров, когда глубокое обучение показало свою важность.
Итак, вы, наконец, нашли работу своей мечты в Deep Learning, но вам интересно, как взломать интервью Deep Learning и какие могут быть возможные вопросы для интервью Deep Learning. Каждое собеседование отличается и объем работы также отличается. Помня об этом, мы разработали самые распространенные вопросы и ответы для глубинных интервью, чтобы помочь вам добиться успеха на собеседовании.
Ниже приведено несколько вопросов для глубокого изучения интервью, которые часто задаются в интервью и также помогут проверить ваши уровни:
Часть 1 - Вопросы по углубленному обучению (базовый уровень)
Эта первая часть охватывает основные вопросы и ответы по глубокому обучению.
1. Что такое глубокое обучение?
Ответ:
Область машинного обучения, которая фокусируется на глубоких искусственных нейронных сетях, которые слабо вдохновлены мозгом. Алексей Григорьевич Ивахненко опубликовал первый генерал по работе в сети Deep Learning. Сегодня он находит применение в различных областях, таких как компьютерное зрение, распознавание речи, обработка естественного языка.
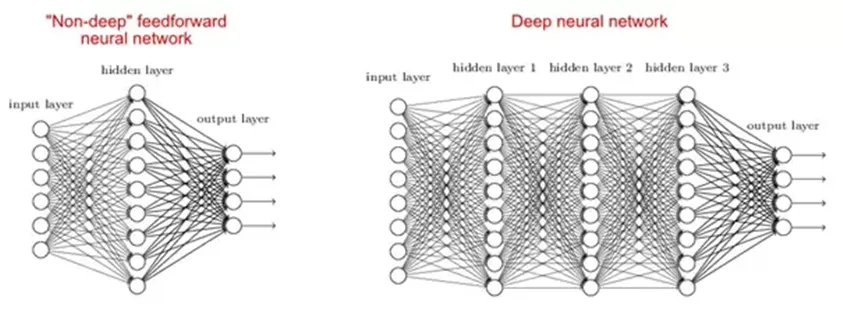
2. Почему глубокие сети лучше мелких?
Ответ:
Существуют исследования, в которых говорится, что как мелкие, так и глубокие сети могут соответствовать любой функции, но поскольку глубокие сети имеют несколько скрытых слоев, часто различных типов, они могут создавать или извлекать более качественные функции, чем мелкие модели с меньшим количеством параметров.
3. Что такое функция стоимости?
Ответ:
Функция стоимости - это мера точности нейронной сети по отношению к данной обучающей выборке и ожидаемому результату. Это одно значение, не векторное, поскольку оно дает производительность нейронной сети в целом. Он может быть рассчитан, как показано ниже, как функция среднего квадрата ошибки:
СКО = 1nΣi = 0n (У я-Yi) 2
Где Y и желаемое значение Y - это то, что мы хотим минимизировать.
Давайте перейдем к следующим вопросам для глубокого обучения.
4. Что такое градиентный спуск?
Ответ:
Градиентный спуск - это в основном алгоритм оптимизации, который используется для определения значений параметров, минимизирующих функцию стоимости. Это итеративный алгоритм, который движется в направлении наискорейшего спуска, определяемого отрицательным значением градиента. Мы вычисляем градиентное снижение функции стоимости для данного параметра и обновляем параметр по следующей формуле:
Θ: = Θ-αd∂ΘJ (Θ)
Где Θ - вектор параметров, α - скорость обучения, J (Θ) - функция стоимости.
5. Что такое обратное распространение?
Ответ:
Обратное распространение - это обучающий алгоритм, используемый для многослойной нейронной сети. В этом методе мы перемещаем ошибку от конца сети ко всем весам внутри сети, что позволяет эффективно вычислять градиент. Это может быть разделено на несколько шагов следующим образом:
Распространение обучающих данных в прямом направлении с целью получения результатов.
UsingПри использовании целевого значения и производной ошибки выходного значения можно вычислить относительно активации выхода.
Hen Затем мы возвращаемся для вычисления производной от ошибки в отношении активации вывода на предыдущем этапе и продолжаем это для всех скрытых слоев.
Sing Используя предварительно рассчитанные производные для вывода и все скрытые слои, мы вычисляем производные ошибок по весам.
«А потом мы обновляем весы.
6. Объясните следующие три варианта градиентного спуска: партия, стохастик и мини-партия?
Ответ:
Стохастический градиентный спуск : здесь мы используем только один обучающий пример для расчета градиента и параметров обновления.
Пакетный градиентный спуск : Здесь мы рассчитываем градиент для всего набора данных и выполняем обновление на каждой итерации.
Мини-пакетный градиентный спуск : это один из самых популярных алгоритмов оптимизации. Это вариант стохастического градиентного спуска, и здесь вместо одного обучающего примера используется мини-партия образцов.
Часть 2 - Вопросы для глубокого изучения интервью (продвинутый уровень)
Давайте теперь посмотрим на расширенные вопросы интервью для глубокого обучения.
7. Каковы преимущества мини-градиентного спуска?
Ответ:
Ниже приведены преимущества мини-градиентного спуска
• Это более эффективно по сравнению со стохастическим градиентным спуском.
• Обобщение путем нахождения плоских минимумов.
• Мини-партии позволяют приблизить градиент всего тренировочного набора, что помогает нам избегать локальных минимумов.
8. Что такое нормализация данных и зачем она нам нужна?
Ответ:
Нормализация данных используется во время обратного распространения. Основным мотивом нормализации данных является уменьшение или устранение избыточности данных. Здесь мы масштабируем значения, чтобы соответствовать определенному диапазону для достижения лучшей конвергенции.
Давайте перейдем к следующим вопросам для глубокого обучения.
9. Что такое инициализация веса в нейронных сетях?
Ответ:
Инициализация веса является одним из очень важных шагов. Плохая инициализация веса может помешать обучению сети, но хорошая инициализация веса помогает обеспечить более быструю сходимость и лучшую общую ошибку. Уклоны могут быть вообще инициализированы к нулю. Правило для установки весов должно быть близко к нулю, не будучи слишком маленьким.
10. Что такое авто-кодировщик?
Ответ:
Автоэнкодер - это автономный алгоритм машинного обучения, который использует принцип обратного распространения, когда целевые значения устанавливаются равными предоставленным входам. Внутренне он имеет скрытый слой, который описывает код, используемый для представления ввода.
Вот некоторые ключевые факты об автоэнкодере:
• Это неконтролируемый алгоритм ML, аналогичный анализу главных компонентов.
• минимизирует ту же функцию цели, что и анализ главных компонентов
• это нейронная сеть
• Целевой выход нейронной сети является ее входом
11. Можно ли подключиться с выхода уровня 4 обратно ко входу уровня 2?
Ответ:
Да, это может быть сделано с учетом того, что выход уровня 4 осуществляется с предыдущего временного шага, как в RNN. Кроме того, мы должны предположить, что предыдущий входной пакет иногда коррелирует с текущим пакетом.
Давайте перейдем к следующим вопросам для глубокого обучения.
12. Что такое машина Больцмана?
Ответ:
Машина Больцмана используется для оптимизации решения проблемы. Работа машины Больцмана в основном заключается в оптимизации веса и количества для данной задачи.
Несколько важных моментов о машине Больцмана -
• Использует рекуррентную структуру.
• Он состоит из стохастических нейронов, которые состоят из одного из двух возможных состояний: 1 или 0.
• Нейроны в этом находятся либо в адаптивном (свободное состояние), либо в зажатом (замороженное состояние).
• Если мы применяем моделируемый отжиг к дискретной сети Хопфилда, то она станет машиной Больцмана.
13. Какова роль функции активации?
Ответ:
Функция активации используется для введения нелинейности в нейронную сеть, помогая ей изучать более сложные функции. Без этого нейронная сеть сможет изучать только линейную функцию, которая является линейной комбинацией ее входных данных.
Рекомендуемые статьи
Это руководство к списку вопросов и ответов для интервью с углубленным изучением, чтобы кандидат мог легко разобраться с этими вопросами. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Узнайте Топ 10 самых полезных вопросов для интервью на HBase
- Полезные вопросы и ответы по машинному обучению
- Топ-5 самых ценных вопросов для интервью с наукой о данных
- Важные вопросы и ответы Ruby Interview