
Введение в Hive Group By
Group By, как следует из названия, сгруппирует запись, которая удовлетворяет определенным критериям. В этой статье мы рассмотрим группу по ВИЧ. В устаревших СУБД, таких как MySQL, SQL и т. Д., Группировка по является одним из самых старых используемых положений. Теперь он нашел свое место аналогичным образом в файловом хранилище данных, известном как HIVE.
Мы знаем, что Hive превзошел многие унаследованные РСУБД в обработке огромных данных, не тратя ни копейки на поставщиков для обслуживания баз данных и серверов. Нам просто нужно настроить HDFS для обработки улья. Как правило, мы переходим к таблицам, потому что конечный пользователь может интерпретировать их структуру и запрашивать их, поскольку файлы будут неуклюжими для них. Но мы должны были сделать это, заплатив поставщикам за предоставление серверов и поддержание наших данных в формате таблиц. Таким образом, Hive обеспечивает экономически эффективный механизм, в котором он использует преимущества файловых систем (способ, которым куст сохраняет данные), а также таблиц (структура таблиц для запросов конечных пользователей).
Группа по
Группировка по использует определенные столбцы из таблицы Hive для группировки данных. Например, представьте, что у вас есть таблица с данными переписи для каждого города всех штатов, где название города и название штата является одним из столбцов. Теперь в запросе, если мы сгруппируем по штатам, тогда все данные из разных городов определенного штата будут сгруппированы вместе, и теперь можно будет легко визуализировать данные лучше, чем был применен способ группировки.
Синтаксис Hive Group By
Общий синтаксис предложения group by приведен ниже:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
или для более простых запросов,
from Group By
Select department, count(*) from the university.college Group By department;
Здесь отдел относится к одному из столбцов таблицы колледжа, которая присутствует в базе данных университета, и ее значение различно на факультетах, таких как искусство, математика, инженерия и т. Д. Теперь давайте рассмотрим пример, демонстрирующий групповое представление.
Я создал образец таблицы deck_of_cards для демонстрации группы. Оператор создания таблицы выглядит следующим образом:
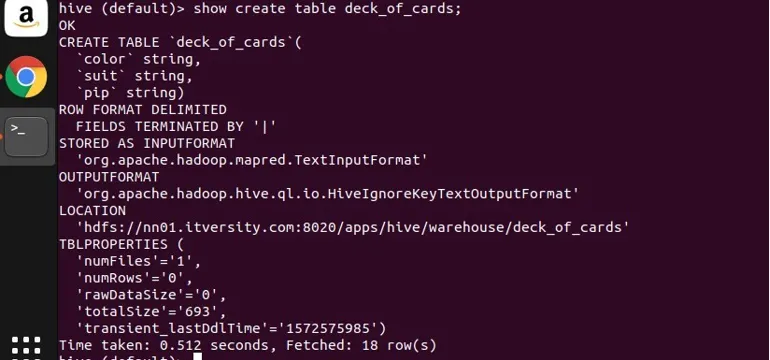
сверху видно, что у него есть три строковых столбца color, suit и pip. Позвольте мне написать запрос, чтобы сгруппировать данные по цвету и получить их счет.
select color, count(*) from deck_of_cards group by color;
Hive в основном берет вышеупомянутый запрос, чтобы преобразовать его в программу уменьшения карты, генерируя соответствующий код Java и файл JAR, а затем выполняет. Этот процесс может занять немного времени, но он определенно может обрабатывать большие данные по сравнению с традиционными СУБД. Смотрите скриншот ниже с подробным журналом для выполнения вышеуказанного запроса.
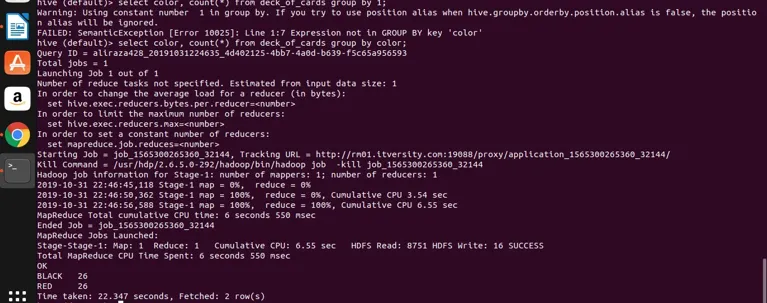
Вы можете видеть, что ЧЕРНЫЙ 26, а КРАСНЫЙ 26.
Теперь давайте применим группировку по двум столбцам (цвет, костюм и счетчик групп) и увидим результат ниже.
Select color, suit, count(*) from deck_of_cards group by color, suit
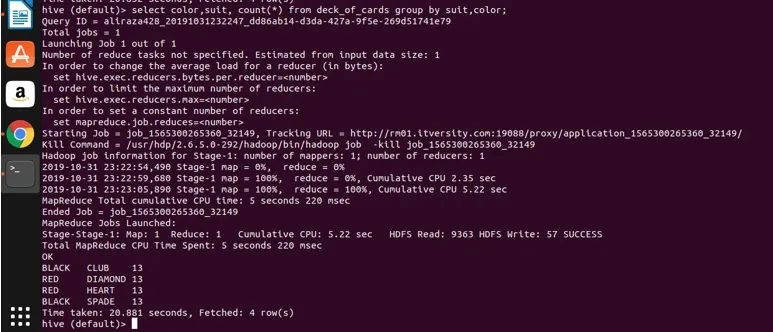
В основном, над Club есть четыре группы: Spade, которые имеют черный цвет, и Diamond и сердце, которые окрашены в красный цвет.
Сохранение результата от группы по причине в другой таблице
Hive также, как и любая другая СУБД, предоставляет возможность вставки данных с помощью операторов создания таблиц. Давайте посмотрим, как сохранить результат из выражения выбора, используя группу, в другую таблицу. Позвольте мне использовать сам запрос выше, где я использовал два столбца в группе по.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
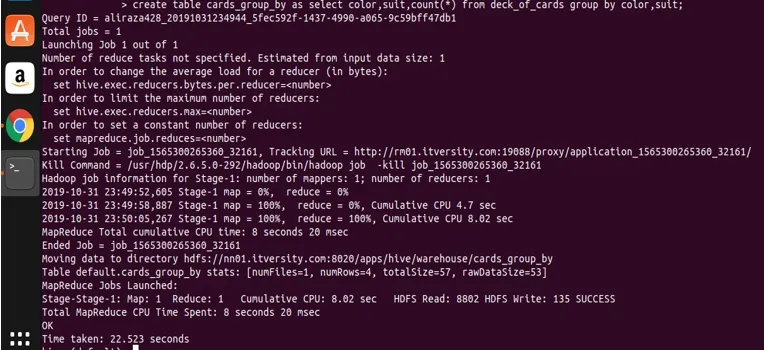
Теперь давайте запросим созданную таблицу, чтобы увидеть и проверить данные.

Теперь давайте ограничим результат группы, используя предложение. Как показано в обобщенном синтаксисе, мы можем применить ограничение к группе, используя:. Здесь я использую таблицу ordser_items, и ее структура следующая из описания оператора.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
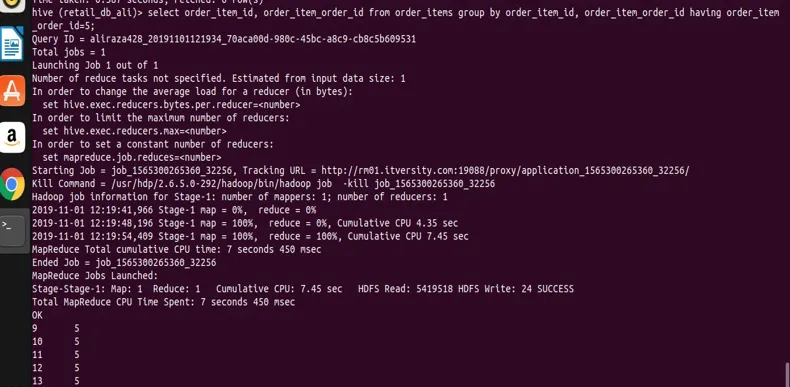
На скриншоте видно, что у нас есть записи только со значением order_item_order_id 5.
Группировка по заявлению
Теперь давайте посмотрим на немного сложные запросы, включающие операторы CASE с группой by. Мы применим это к таблице order_items. Ниже мы увидим, что мы можем классифицировать неагрегирующие столбцы, к которым мы не можем применить предложение group by напрямую.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
давайте выполним это в улье для результатов
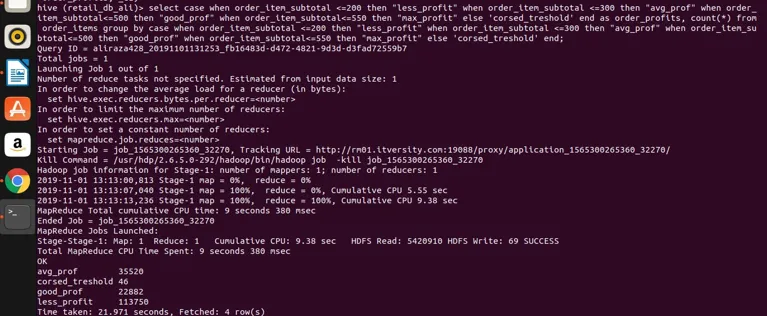
Вывод - Hive Group By
Таким образом, мы можем видеть, что мы сгруппировали order_item_subtotal по четырем различным категориям (если вы заметили, что order_item_subtotal является неагрегирующим столбцом, и прямая группа не может быть применена к нему), и мы сгруппировали их вместе и получили их значения для значения, которые удовлетворяют диапазону, как определено в выражении выбора. Здесь простое правило, если столбец неагрегирующий, а наше выражение выбора является сложным, то что бы там ни было в выражении выбора, которое также должно присутствовать в выражении предложения group by. Итак, мы увидели, как известная группа предложений RDBMS может также применяться к Hive без каких-либо ограничений. Это может быть применено к простым выражениям выбора. Агрегирование и фильтрация выражений, выражений объединения и сложных выражений CASE.
Рекомендуемые статьи
Это руководство по Hive Group By. Здесь мы обсуждаем group by, синтаксис, примеры группы hive с различными условиями и реализацией. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Присоединяется в Улей
- Что такое улей?
- Улей Архитектура
- Функция улья
- Улей Заказать
- Улей Установка
- 6 лучших типов соединений в MySQL с примерами