
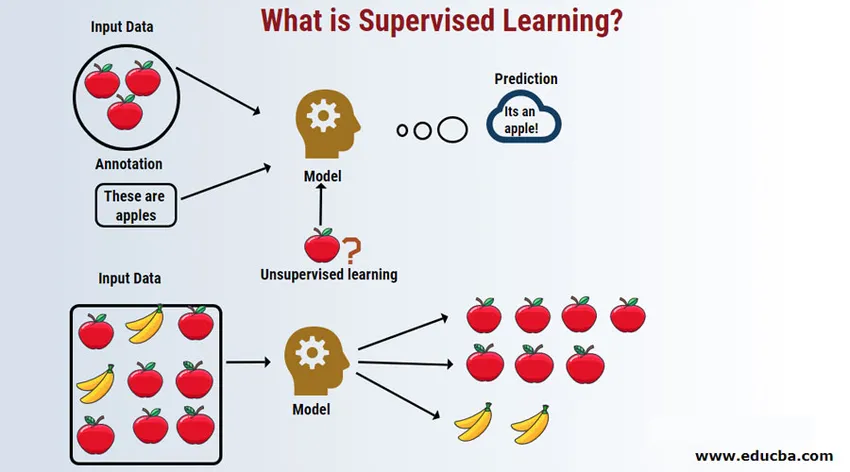
Введение в контролируемое обучение
Контролируемое обучение - это область машинного обучения, в которой мы работаем над прогнозированием значений с использованием маркированных наборов данных. Помеченные входные наборы данных называются независимой переменной, в то время как прогнозируемые результаты называются зависимой переменной, потому что они зависят от независимой переменной для своих результатов. Например, у всех нас есть папка спама в нашей учетной записи электронной почты (например, Gmail), которая автоматически обнаруживает для вас большинство электронных писем со спамом и мошенничеством с точностью более 95%. Он работает на основе контролируемой модели обучения, где у нас есть обучающий набор помеченных данных, который в данном случае представляет собой помеченную спам-электронную почту, помеченную пользователями. Эти обучающие наборы используются для обучения, которое в дальнейшем будет использоваться для классификации новых писем как спама, если они соответствуют категории.
Работаем над контролируемым машинным обучением
Давайте разберемся с контролируемым машинным обучением на примере. Допустим, у нас есть корзина с фруктами, которая заполнена различными видами фруктов. Наша работа состоит в том, чтобы классифицировать фрукты в зависимости от их категории.
В нашем случае мы рассмотрели четыре типа фруктов: яблоки, бананы, виноград и апельсины.
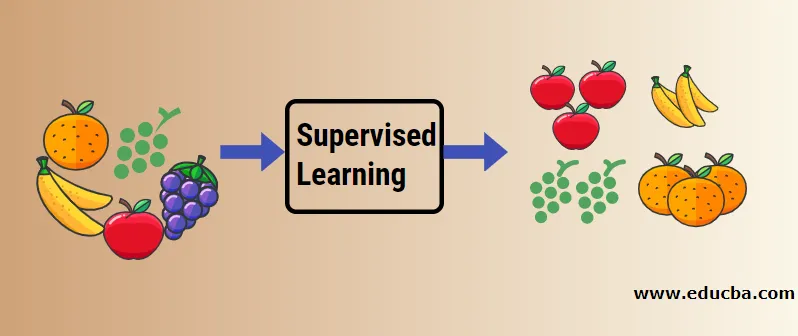
Теперь мы попытаемся упомянуть некоторые из уникальных характеристик этих фруктов, которые делают их уникальными.
|
S № | Размер | цвет | форма |
Имя |
|
1 | Небольшой | зеленый | От круглой до овальной формы, цилиндрическая форма |
виноград |
|
2 | большой | красный | Округлая форма с углублением наверху |
яблоко |
|
3 | большой | желтый | Длинный изогнутый цилиндр |
Банан |
| 4 | большой | апельсин | Округлая форма |
апельсин |
Теперь позвольте нам сказать, что вы взяли фрукт из корзины с фруктами, вы посмотрели на его особенности, например, на его форму, размер и цвет, а затем вы пришли к выводу, что цвет этого фрукта красный, размер, если большой форма округлой формы с углублением вверху, следовательно, это яблоко.
- Точно так же вы делаете то же самое для всех остальных оставшихся фруктов.
- Крайний правый столбец («Название фрукта») называется переменной ответа.
- Таким образом, мы формулируем контролируемую модель обучения, и теперь каждому новичку (скажем, роботу или пришельцу) с заданными свойствами будет легко сгруппировать фрукты одного типа.
Типы контролируемого алгоритма машинного обучения
Давайте рассмотрим различные типы алгоритмов машинного обучения:
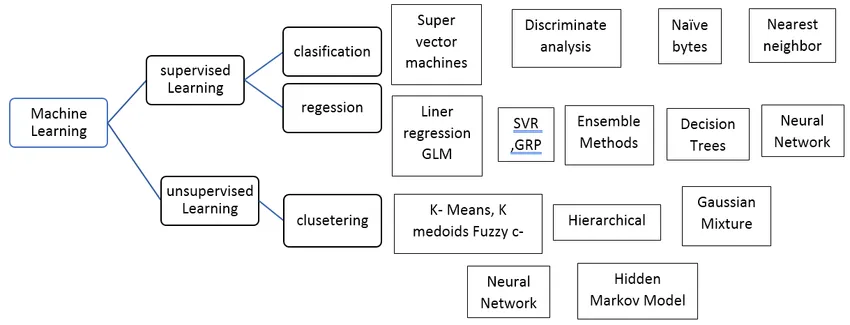
Регресс:
Регрессия используется для прогнозирования одного значения вывода с использованием набора обучающих данных. Выходное значение всегда вызывается как зависимая переменная, в то время как входные данные известны как независимая переменная. У нас есть различные типы регрессии в контролируемом обучении, например,
- Линейная регрессия - здесь у нас есть только одна независимая переменная, которая используется для прогнозирования выходных данных, т.е. зависимая переменная.
- Множественная регрессия - здесь мы имеем более одной независимой переменной, которая используется для прогнозирования выходных данных, т.е. зависимой переменной.
- Полиномиальная регрессия - здесь график между зависимой и независимой переменными следует полиномиальной функции. Например, сначала память увеличивается с возрастом, затем она достигает порога в определенном возрасте, а затем она начинает уменьшаться с возрастом.
Классификация:
Классификация контролируемых алгоритмов обучения используется для группировки похожих объектов в уникальные классы.
- Бинарная классификация. Если алгоритм пытается сгруппировать 2 отдельные группы классов, он называется бинарной классификацией.
- Мультиклассовая классификация - если алгоритм пытается сгруппировать объекты в более чем 2 группы, он называется мультиклассовой классификацией.
- Сила - Алгоритмы классификации обычно работают очень хорошо.
- Недостатки - склонны к переоснащению и могут быть без ограничений. Например - Email Spam классификатор
- Логистическая регрессия / классификация - когда переменная Y является двоичной категорией (т. Е. 0 или 1), мы используем логистическую регрессию для прогнозирования. Например - Прогнозирование, является ли данная транзакция по кредитной карте мошеннической или нет.
- Наивные байесовские классификаторы - Наивный байесовский классификатор основан на теореме Байеса. Этот алгоритм обычно лучше всего подходит, когда размерность входов высока. Он состоит из ациклических графов, имеющих один родительский и много дочерних узлов. Дочерние узлы не зависят друг от друга.
- Деревья решений - Дерево решений - это древовидная структура, похожая на диаграмму, которая состоит из внутреннего узла (тест по атрибуту), ветви, которая обозначает результат теста, и конечных узлов, которые представляют распределение классов. Корневой узел - это самый верхний узел. Это очень широко используемый метод, который используется для классификации.
- Машина опорных векторов. Машина опорных векторов или SVM выполняет классификацию, находя гиперплоскость, которая должна максимизировать разницу между двумя классами. Эти машины SVM связаны с функциями ядра. Области, где широко используются SVM, это биометрия, распознавание образов и т. Д.
преимущества
Ниже приведены некоторые преимущества контролируемых моделей машинного обучения:
- Производительность моделей может быть оптимизирована в зависимости от опыта пользователя.
- Контролируемое обучение дает результаты с использованием предыдущего опыта, а также позволяет собирать данные.
- Управляемые алгоритмы машинного обучения могут быть использованы для реализации ряда реальных проблем.
Недостатки
Недостатки контролируемого обучения заключаются в следующем:
- Усиление обучения контролируемых моделей машинного обучения может занять много времени, если набор данных больше.
- Классификация больших данных иногда представляет большую проблему.
- Возможно, придется иметь дело с проблемами переоснащения.
- Нам нужно много хороших примеров, если мы хотим, чтобы модель работала хорошо, пока мы тренируем классификатор.
Хорошая практика при построении моделей обучения
Это хорошая практика при построении контролируемых обучающих моделей машин: -
- Перед построением любой хорошей модели машинного обучения необходимо выполнить процесс предварительной обработки данных.
- Нужно выбрать алгоритм, который лучше всего подходит для данной проблемы.
- Нам нужно решить, какой тип данных будет использоваться для учебного набора.
- Необходимо определиться со структурой алгоритма и функцией.
Вывод
В нашей статье мы узнали, что такое контролируемое обучение, и увидели, что здесь мы обучаем модель, используя помеченные данные. Затем мы приступили к работе моделей и их различных типов. Мы наконец увидели преимущества и недостатки этих контролируемых алгоритмов машинного обучения.
Рекомендуемые статьи
Это руководство к тому, что такое контролируемое обучение? Здесь мы обсуждаем понятия, как это работает, типы, преимущества и недостатки контролируемого обучения. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Что такое глубокое обучение
- Контролируемое обучение против глубокого обучения
- Что такое синхронизация в Java?
- Что такое веб-хостинг?
- Способы создания дерева решений с преимуществами
- Полиномиальная регрессия | Использование и особенности