

Что такое кластерный анализ
Кластерный анализ группирует данные на основе характеристик, которыми они обладают. Кластерный анализ группирует объекты на основе факторов, которые делают их похожими. Кластерный анализ иначе называется анализом сегментации или анализом таксономии. Кластерный анализ не различает зависимые и независимые переменные. Кластерный анализ используется в самых разных областях, таких как психология, биология, статистика, интеллектуальный анализ данных, распознавание образов и другие социальные науки.
Цель кластерного анализа
Основная задача кластерного анализа - рассмотреть неоднородность в каждом наборе данных. Другие задачи кластерного анализа
- Описание таксономии. Определение групп в данных
- Упрощение данных - возможность анализировать группы похожих наблюдений вместо всех отдельных наблюдений.
- Генерирование или проверка гипотезы. Разработка гипотезы на основе характера данных или проверка ранее высказанной гипотезы.
- Идентификация отношений - упрощенная структура из кластерного анализа, которая описывает отношения
Существует две основные цели кластерного анализа - понимание и полезность.
В условиях понимания, кластерный анализ группирует объекты, которые имеют некоторые общие характеристики
В целях использования утилиты кластерный анализ предоставляет характеристики каждого объекта данных для кластеров, к которым они принадлежат.
Кластерный анализ неразрывно связан с факторным анализом и дискриминантным анализом.
Вы должны задать себе несколько вопросов кластерного анализа, прежде чем начать с ним
- Какие переменные актуальны?
- Достаточно ли размера выборки?
- Можно ли обнаружить выбросы и нужно ли их удалить?
- Как следует измерять сходство объектов?
- Должны ли данные быть стандартизированы?

Типы кластеров
Существует три основных типа кластеризации
- Иерархическая кластеризация - которая содержит агломерационный и разделительный метод
- Разделение на группы - содержит K-средние, нечеткие K-средние, Isodata
- Плотность на основе кластеризации - есть Денклуст, CLUPOT, Mean Shift, SVC, Parzen-Watershed под ним
Допущения в кластерном анализе
В кластерном анализе всегда есть два предположения
- Предполагается, что выборка является представителем населения
- Предполагается, что переменные не коррелированы. Даже если переменные коррелируют, удалите коррелированные переменные или используйте меры расстояния, которые компенсируют корреляцию.
Шаги в кластерном анализе
-
- Шаг 1: Определите проблему
- Шаг 2: Определите подходящую меру сходства
- Шаг 3: Решите, как группировать объекты
- Шаг 4: Определите количество кластеров
- Шаг 5: интерпретировать, описать и проверить кластер
Кластерный анализ в SPSS
В SPSS вы можете найти опцию кластерного анализа в опции Анализ / Классификация. В SPSS есть три метода кластерного анализа - кластер K-Means, иерархический кластер и двухступенчатый кластер.
Кластерный метод K-Means классифицирует данный набор данных через фиксированное количество кластеров. Этот метод прост для понимания и дает лучший результат, когда данные хорошо отделены друг от друга.
Двухшаговый кластерный анализ - это инструмент, предназначенный для обработки больших наборов данных. Создает кластеры как по категориальным, так и по непрерывным переменным.
Иерархический кластер является наиболее часто используемым методом кластерного анализа. Он объединяет случаи в однородные кластеры, объединяя их через ряд последовательных шагов.
Иерархический кластерный анализ содержит три этапа
- Рассчитать расстояние
- Связать кластеры
- Выбор решения, выбрав правильное количество кластеров
Ниже приведены шаги для выполнения анализа иерархического кластера в SPSS.
- Первый шаг - выбрать переменные, которые должны быть сгруппированы. Ниже диалоговое окно объясняет это вам
- Нажав на параметр статистики в приведенном выше диалоговом окне, вы получите диалоговое окно, в котором вы хотите указать вывод
- В диалоговых окнах графиков добавьте дендрограмму. Дендрограмма - это графическое представление метода иерархического кластерного анализа. Он показывает, как кластеры объединяются на каждом этапе, пока он не образует единый кластер.
- Метод диалогового окна имеет решающее значение. Вы можете упомянуть расстояние и метод кластеризации здесь. В SPSS есть три показателя для интервала, количества и двоичных данных.
- Квадратное евклидово расстояние - это сумма квадратов разностей без учета квадратного корня.
- В счетчиках вы можете выбрать между мерой площади Ци и площади Фи
- В разделе Binary у вас есть много вариантов для выбора. Квадратное евклидово расстояние - лучший вариант для использования.
- Следующим шагом является выбор метода кластера. Всегда рекомендуется использовать Single Linkage или Nearest Neighbor, поскольку это легко помогает идентифицировать выбросы. После определения выбросов вы можете использовать метод Уорда.
- Последний шаг - Стандартизация
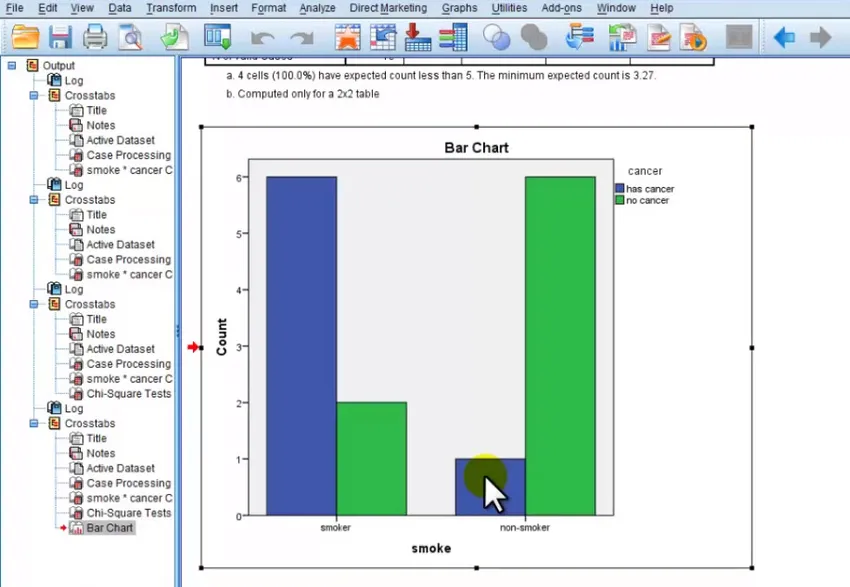
Критика кластерного анализа
Наиболее распространенные критические замечания перечислены ниже
- Это описательный, теоретический и не логичный вывод.
- Он будет производить кластеры независимо от фактического существования какой-либо структуры
- Он не может использоваться широко, поскольку он полностью зависит от переменных, используемых в качестве основы для меры подобия
Что такое факторный анализ?
Факторный анализ - это исследовательский анализ, который помогает сгруппировать похожие переменные в измерения. Его можно использовать для упрощения данных за счет уменьшения размеров наблюдений. Факторный анализ имеет несколько различных методов ротации.
Факторный анализ используется в основном для сокращения данных.
Существует два типа факторного анализа - исследовательский и подтверждающий
- Исследовательский метод используется, когда у вас нет заранее определенного представления о структурах или измерениях в наборе переменных.
- Подтверждающий метод используется, когда вы хотите проверить конкретную гипотезу о структурах или измерениях в наборе переменных.
Цели факторного анализа
Есть две основные цели факторного анализа, которые упомянуты ниже
- Определение основных факторов - это включает кластеризацию переменных в однородные наборы, создание новых переменных и помощь в получении знаний о категориях
- Скрининг переменных. Он полезен при регрессии и определяет группы, позволяющие выбрать одну переменную, которая представляет множество.
Допущения факторного анализа
Есть четыре основных предположения факторного анализа, которые упомянуты ниже
- Модели обычно основаны на линейных отношениях
- Предполагается, что собранные данные имеют интервальное масштабирование.
- Мультиколлинеарность в данных желательна, так как цель состоит в том, чтобы выяснить взаимосвязанный набор переменных
- Данные должны быть открытыми и отзывчивыми для факторного анализа. Не должно быть так, чтобы переменная коррелировала только с самим собой, и никакой корреляции с любой другой переменной не существует. Факторный анализ не может быть сделан на таких данных.
Типы Факторинга
- Факторинг главных компонентов - наиболее часто используемый метод, в котором весовые коэффициенты вычисляются для извлечения максимально возможной дисперсии и продолжается до тех пор, пока не останется значимой дисперсии.
- Канонический факторный анализ - Находит факторы, которые имеют наибольшую каноническую корреляцию с наблюдаемыми переменными
- Общий факторный анализ - ищет наименьшее количество факторов, которые могут объяснить общую дисперсию набора переменных
- Факторинг изображения - на основе корреляционной матрицы, где каждая переменная прогнозируется из других с использованием множественной регрессии
- Альфа-Факторинг - максимизирует надежность факторов
- Факторная модель регрессии. Комбинация факторной модели и модели регрессии, факторы которой частично известны
Критерии факторного анализа
-
Критерии собственных значений
- Представляет количество отклонений в исходных переменных, связанных с фактором
- Сумма квадрата факторных нагрузок каждой переменной на фактор представляет собой собственное значение
- Факторы с собственными значениями, превышающими 1, 0, сохраняются
-
Критерии Scree Plot
- График собственных значений в зависимости от количества факторов, в порядке извлечения.
- Форма сюжета определяет количество факторов
-
Процент критериальных отклонений
- Число извлеченных факторов выясняется так, что увеличивающийся процент дисперсии, извлекаемой факторами, достигает уровня удовлетворенности.
-
Критерии значимости теста
- Статистическая значимость отдельных собственных значений выясняется, и сохраняются только те факторы, которые являются статистически значимыми
Факторный анализ используется в различных областях, таких как психология, социология, политология, образование и психическое здоровье.
Факторный анализ в SPSS
В SPSS опцию факторного анализа можно найти в разделе Анализ à Уменьшение размеров à Фактор
- Начните с добавления переменных в раздел списка переменных
- Перейдите на вкладку «Описательный» и добавьте несколько статистических данных, в соответствии с которыми проверяются предположения факторного анализа.
- Выберите опцию извлечения, которая позволит вам выбрать метод извлечения и сократить значение для извлечения
- Основные компоненты (PCA) - это метод извлечения по умолчанию, который извлекает даже некоррелированные линейные комбинации переменных. PCA может использоваться, когда корреляционная матрица является единственной. Это очень похоже на канонический корреляционный анализ, где первый фактор имеет максимальную дисперсию, а следующие факторы объясняют меньшую часть дисперсии.
- Второй наиболее общий анализ - факторинг по главной оси. Это идентифицирует скрытые конструкции позади наблюдений.
- Следующим шагом является выбор метода вращения. Наиболее часто используемый метод - Varimax. Этот метод упрощает интерпретацию факторов.
- Второй метод - Quartimax. Этот метод вращает факторы, чтобы минимизировать количество факторов. Это упрощает интерпретацию наблюдаемой переменной.
- Следующим методом является Equamax, который является комбинацией двух вышеупомянутых методов.
- В диалоговом окне, нажав на «параметры», вы можете управлять отсутствующими значениями
- Прежде чем сохранять результаты в наборе данных, сначала запустите факторный анализ, проверьте предположения и подтвердите, что результаты значимы и полезны.
Кластерный анализ против факторного анализа
Как кластерный анализ, так и факторный анализ являются методом обучения без надзора, который используется для сегментации данных. Многие исследователи, которые являются новичками в этой области, считают, что кластерный анализ и факторный анализ похожи. Это может показаться похожим, но они отличаются во многих отношениях. Различия между кластерным анализом и факторным анализом перечислены ниже
-
Задача
Задачи кластерного и факторного анализа разные. Целью кластерного анализа является разделение наблюдений на однородные и отдельные группы. Факторный анализ, с другой стороны, объясняет однородность переменных в результате сходства значений.
-
сложность
Сложность является еще одним фактором, от которого отличаются кластерный и факторный анализ. Размер данных влияет на анализ по-разному. Если размер данных слишком велик, он становится вычислительно сложным в кластерном анализе.
-
Решение
Решение проблемы более или менее похоже как в факторном, так и в кластерном анализе. Но факторный анализ обеспечивает лучшее решение для исследователя в лучшем аспекте. Кластерный анализ не дает наилучшего результата, так как все алгоритмы кластерного анализа вычислительно неэффективны.
-
Приложения
Факторный анализ и кластерный анализ по-разному применяются к реальным данным. Факторный анализ подходит для упрощения сложных моделей. Это сводит большой набор переменных к гораздо меньшему набору факторов. Исследователь может разработать набор гипотез и выполнить анализ факторов, чтобы подтвердить или опровергнуть эту гипотезу.
Кластерный анализ подходит для классификации объектов на основе определенных критериев. Исследователь может измерить определенные аспекты группы и разделить их на конкретные категории с помощью кластерного анализа.
Есть также много других отличий, которые упомянуты ниже
- Кластерный анализ пытается сгруппировать случаи, тогда как факторный анализ пытается сгруппировать признаки.
- Кластерный анализ используется для поиска небольших групп случаев, которые представляют данные в целом. Факторный анализ используется, чтобы найти меньшую группу функций, которые представляют оригинальные наборы данных.
- Наиболее важной частью кластерного анализа является определение количества кластеров. В основном методы кластеризации делятся на два - агломерационный метод и метод разбиения. Агломерационный метод начинается с каждого случая в своем кластере и останавливается при достижении критерия. Метод разбиения начинается со всех случаев в одном кластере.
- Факторный анализ используется для определения базовой структуры в наборе данных.
Вывод
Надеюсь, что эта статья помогла бы вам понять основы кластерного анализа и факторного анализа и различия между ними.
Связанные курсы: -
- Курс кластерного анализа