

Как установить Apache
Перед тем, как приступить к установке части Apache, у нас будет общий обзор Apache и его использования в науке о данных.
Что такое Apache?

Apache Web Server - это HTTP-сервер, который представляет веб-сайты посетителям, которые приходят на ваш сервер. Поэтому, если вы хотите развернуть веб-сайт для бизнеса или вашей организации, вы, скорее всего, будете использовать Apache для этого.
Существуют и другие HTTP-серверы, такие как IIS, но Apache - это стандарт, который используют большинство людей, будь то в Linux, Windows или Mac. По умолчанию Apache используется большинством людей, потому что он хорошо известен, очень надежен и бесплатен.
Однако с Apache нужно понять одну вещь: поскольку это HTTP-сервер, поэтому, если вы установите его на Linux, Windows или Mac, все, что вам нужно сделать, это представить статические веб-сайты посетителям вашего сервера. Следовательно, если вы кодируете веб-сайт HTML без дополнительных языков программирования, кроме JavaScript, вы можете использовать его только с сервером Apache. Вы можете подключить все свои теги к серверу Apache и представить его своим посетителям.
Как Apache использовал в Data Science?
Наука Данных - самая востребованная область исследований в современном мире. Data Scientist считается самой сексуальной работой в 21-м веке, когда специалисты из разных дисциплин хотят учиться и стать Data Scientist. Apache играет решающую роль в любом энтузиасте науки о данных, так как им необходимы достаточные знания об экосистеме Apache Hadoop.
Apache Hadoop Ecosystem
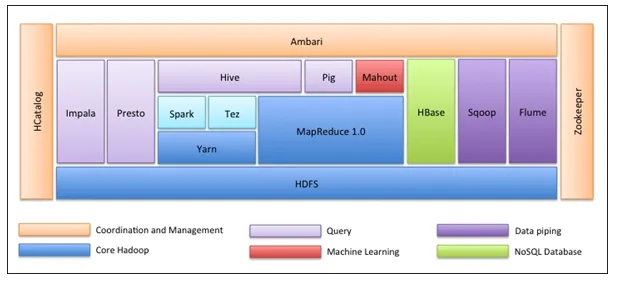
Самое первое, что экосистема Hadoop - это не один инструмент. Это не язык программирования или отдельная структура. Это группа инструментов, которые используются различными компаниями в разных доменах для решения множества задач. Мы рассмотрим каждый инструмент один за другим ниже:
- Apache HDFS (распределенная файловая система Hadoop) - это устройство хранения Hadoop, которое может хранить структурированные, полуструктурированные и неструктурированные данные. HDFS имеет метаданные, которые поддерживают файл журнала о сохраненных данных. Он состоит из двух компонентов - NameNode и DataNode.
- Apache Yarn - это посредник ресурсов, который выполняет все операции обработки, такие как планирование задач, распределение ресурсов и т. Д. Он имеет две службы. Первая - это Resource Manager, который планирует приложения, работающие поверх Yarn. Второй - это Node Manager, который контролирует использование ресурсов .
- Apache Map Reduce - это компонент обработки данных Hadoop, который обрабатывает большие наборы данных с использованием распределенных и параллельных вычислений на основе функций Map, Sort и Shuffle и Reduce. Функция карты фильтрует данные, затем выполняется сортировка и перемешивание, а в конце функция Уменьшения агрегирует и суммирует результат.
- Apache Pig используется в основном в ETL. Он состоит из двух частей - Pig Latin и Pig runtime. Pig Latin - это язык, используемый для обработки данных с использованием запроса, тогда как Pig runtime - это среда выполнения. Одна строка Pig Latin почти равна 100 строкам кода Map Reduce. Процесс включает в себя сначала загрузить данные, а затем сгруппировать, отсортировать, отфильтровать и сохранить их в HDFS.
- Apache Hive использует SQL-подобный запрос для анализа данных в распределенной среде. Он состоит из двух компонентов - командной строки Hive и сервера JDBC / ODBC, а используемый язык называется HiveQL.
- Apache Mahout - это библиотека машинного обучения, написанная на Java и используемая для создания приложений машинного обучения, таких как кластеризация, классификация или регрессия. Он имеет разные алгоритмы, встроенные для разных случаев использования.
- Apache HBase - это база данных NoSQL, написанная на Java, которая работает на Hadoop. Он построен на основе Google BigTable и способен обрабатывать все типы данных.
- Apache Sqoop - это один из инструментов приема данных, который используется для объемной структурированной передачи данных между RDBMS и Hadoop.
- Apache Flume - это еще один инструмент приема данных, который используется для передачи полуструктурированных и неструктурированных данных между Hadoop и другими источниками данных.
- ZooKeeper является координатором, который обеспечивает координацию между различными инструментами в экосистеме Hadoop.
- Apache Ambari - менеджер кластеров, который обеспечивает, управляет кластерами Hadoop, а также следит за их состоянием и состоянием.
- Apache Tez - это новый инструмент в экосистеме Hadoop, который ускоряет обработку запросов Hadoop.
- Apache Presto - это механизм распределенных SQL-запросов с открытым исходным кодом, который обеспечивает возможность межплатформенных запросов.
- Apache HCatalog - это система управления метаданными и таблицами для Hadoop, которая обеспечивает взаимодействие между инструментами обработки данных. Это также помогает пользователям выбирать лучшие инструменты для своей среды.
- Apache Spark является наиболее широко используемой и популярной средой среди Data Scientist. Это высокоскоростная кластерная вычислительная система, которая оптимизирует использование ресурсов в случае множества итерационных задач. Это дает гибкость как для пакетной обработки, так и для анализа данных в реальном времени.
Ниже приведены шаги для установки Apache
До сих пор мы узнали об Apache и о том, как он полезен для тех, кто хочет изучать Data Science или Big Data Analytics. Теперь мы углубимся и установим apache для окон, основываясь на следующих шагах.
- Перейдите на https://httpd.apache.org/ и нажмите ссылку «Загрузить» в разделе «Выпущен Apache httpd 2.4.38».

- Вы перейдете на следующую страницу и нажмите «Файлы для Microsoft Windows».
- Нажмите на Apache Lounge.

- Вы можете загрузить 32-разрядный или 64-разрядный файл ZIP в зависимости от операционной системы Windows. Мы будем загружать 64-битную версию здесь. Нажмите на соответствующую ссылку .zip для загрузки.

- Теперь требуется C ++ Redistributable Visual Studio 2017. Поэтому мы будем загружать его по соответствующей 32-битной или 64-битной ссылке

- После того, как оба файла были загружены, мы пойдем в загруженный каталог и сначала установим C ++ Redistributable Visual Studio 2017. Дважды щелкните файл .exe.

- Проверьте «Я согласен» и нажмите «Установить».

- Идет установка Apache.
- Как только оно будет завершено, вы получите следующее сообщение. Нажмите Закрыть, чтобы завершить установку.
- Теперь перейдите в папку, в которую вы загружаете zip-файл Apache. Щелкните правой кнопкой мыши и выберите извлечение здесь.
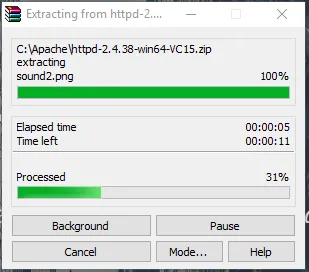
- Теперь у нас будет создана папка Apache24. Скопируйте эту папку на диск C, а затем мы добавим путь к системным переменным среды.
Перейдите в Свойства системы -> вкладка «Дополнительно» -> нажмите кнопку «Переменные среды» ниже.
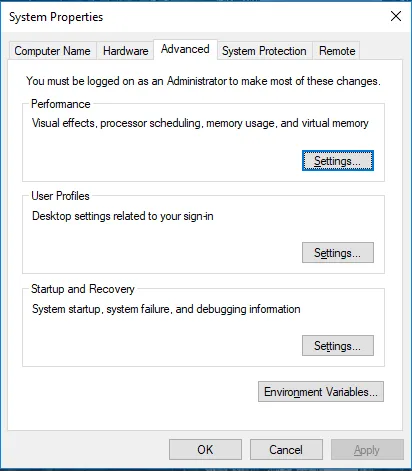
- В разделе «Переменные» найдите «Путь» и нажмите «Изменить».
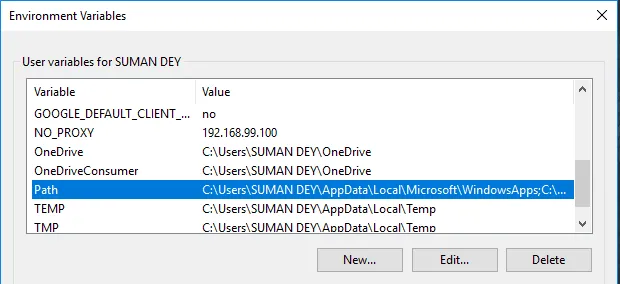
- Нажмите «Обзор» -> «Перейти к диску C», папка Apache24 -> «Выбрать папку bin» -> «ОК».
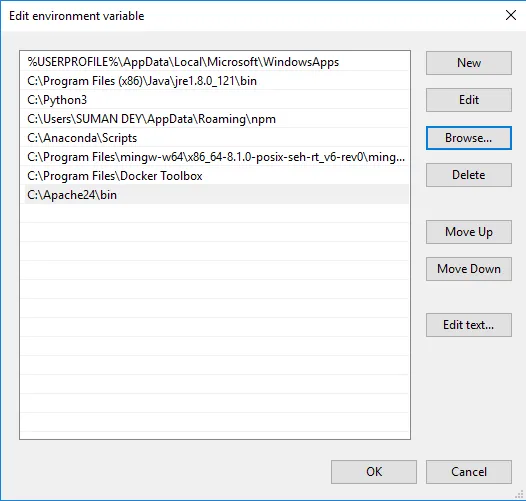
- Мы установим Apache в качестве службы Windows. Запустите командную строку от имени администратора. Введите httpd –k install и нажмите ввод.
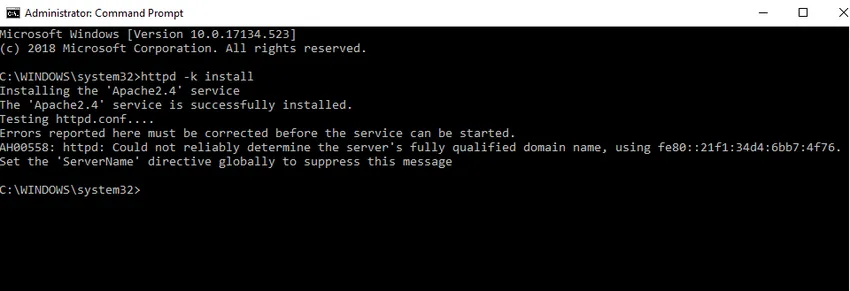
- Мы проверим установку службы Apache. Нажмите на значок Windows и введите службы. Нажмите на приложение Services и найдите сервис с именем Apache24.

- Чтобы запустить сервер Apache, щелкните по нему правой кнопкой мыши и нажмите «Пуск». Статус изменится на «Бег».
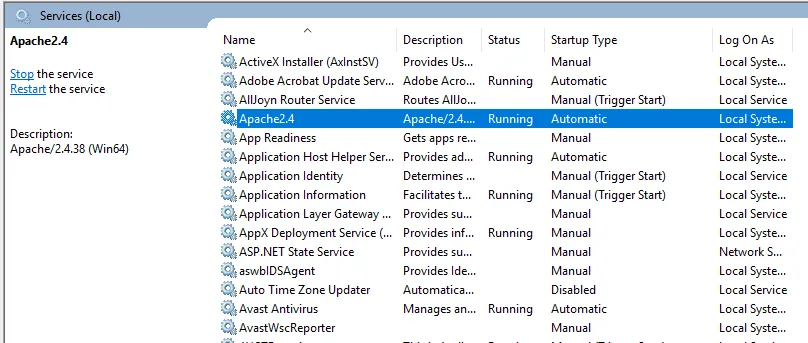
- Мы можем проверить с помощью браузера. Откройте браузер и перейдите по адресу http: // localhost и нажмите ввод. Сообщение с надписью "Это работает!" появится, чтобы подтвердить успешную установку Apache.
Рекомендуемые статьи
Это было руководство о том, как установить Apache. Здесь мы обсудили инструкции и различные шаги для установки Apache. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Apache Интервью Вопросы
- Апач Спарк против Апач Флинк
- Apache Hadoop против Apache Spark
- Апач Кафка против Флюм
- Кафка против Кинезис | Основные отличия