

Что такое большие данные и Hadoop?
Данные растут в геометрической прогрессии каждый день, и с такими растущими данными возникает необходимость их использования. Как и в прежние времена, у нас были гибкие диски для хранения данных, и передача данных также была медленной, но в настоящее время их недостаточно, и используется облачное хранилище, поскольку у нас есть терабайты данных. В сегодняшнем мире у нас есть социальные сети, способствующие росту данных. Он состоит из поведения людей, мышления и нескольких других аспектов. Говорят, что каждую минуту на YouTube загружается 300 часов видео, более 20 миллионов фотографий загружаются в Facebook и многие другие. Более того, нет правильной структуры загружаемых данных, что является самой большой проблемой для обработки этих данных.
Поскольку огромные данные генерируются с высокой скоростью, традиционные системы RDBMS не смогли справиться с таким быстрым темпом роста. Более того, они также не способны обрабатывать неструктурированные данные. Стало очень трудно справляться с таким огромным количеством разнородных данных, быстро растущих, и обрабатывать эти данные с высокой скоростью обработки. Таким образом, возникла необходимость в такой системе, которая способна эффективно обрабатывать большой набор данных. Следовательно, для решения сценария Hadoop возникла. HDFS - это компонент Hadoop, который решает проблему хранения большого набора данных с помощью распределенного хранилища, а YARN - это компонент, который решает проблему обработки, значительно сокращая время обработки.
Hadoop - это программная среда с открытым исходным кодом для хранения и обработки больших наборов данных с использованием распределенного большого кластера аппаратного обеспечения. Он был разработан Дугом Каттингом и Майклом Дж. Кафареллой и лицензирован под Apache. Он написан с использованием Java и был разработан на основе статьи, написанной Google для системы MapReduce, и в нем применяются концепции функционального программирования. Это надежный, экономичный, гибкий и масштабируемый.
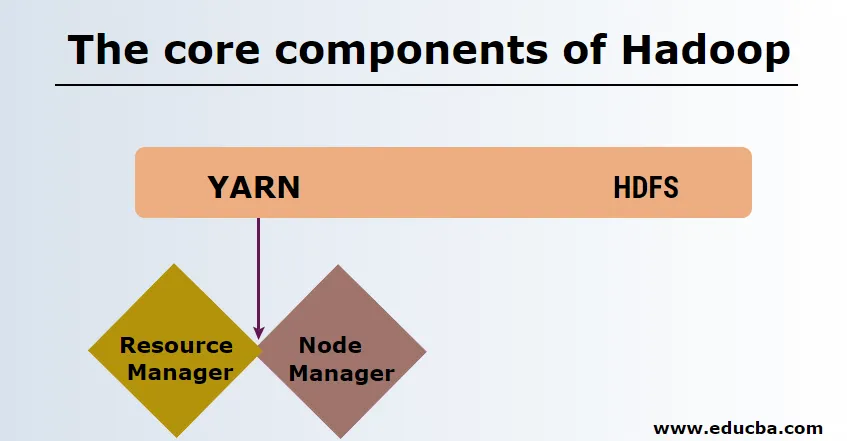
Основные компоненты Hadoop
Основные компоненты Hadoop следующие
-
HDFS
HDFS или распределенная файловая система Hadoop имеют Namenode и узел данных. Namenode - это главный узел, на котором работает мастер-демон, который управляет узлами данных и отслеживает все операции. Датододы - это подчиненные устройства, где данные хранятся.
-
ПРЯЖА
YARN состоит из двух основных компонентов:
1. ResourceManager: он работает на главном узле, управляет всеми ресурсами и планирует все приложения. Он имеет Планировщик и ApplicationManager.
2. NodeManager: он работает на каждом подчиненном узле и отвечает за управление контейнерами и мониторинг использования ресурсов.
Несколько компонентов Hadoop
Есть несколько компонентов Hadoop, такие как свинья, улей, sqoop, flume, mahout, oozie, zookeeper, HBase и т. Д.
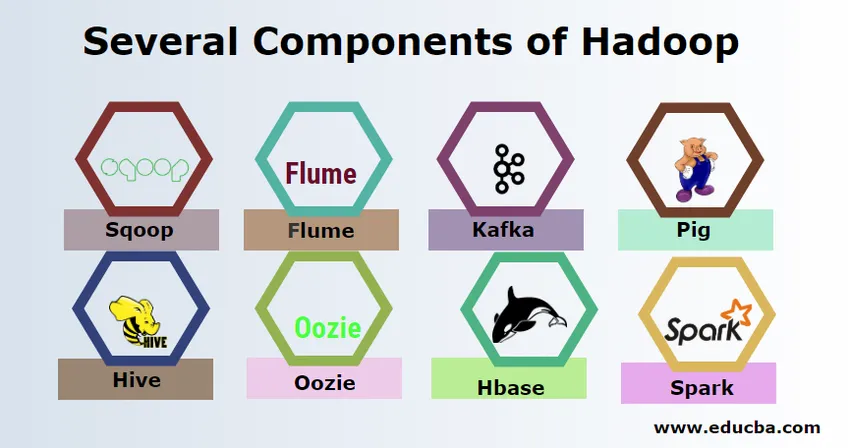
- Sqoop - используется для импорта и экспорта данных из RDBMS в Hadoop и наоборот.
- Flume - используется для передачи данных в реальном времени в Hadoop.
- Kafka - это система обмена сообщениями, используемая для передачи данных в реальном времени в Hadoop.
- Свинья - используется в качестве языка сценариев для обработки данных.
- Hive - это структура хранилища данных, построенная на HDFS, так что пользователи, знакомые с SQL, могут выполнять запросы для получения данных. Эти запросы называются HiveQL.
- Oozie - используется для планирования рабочего процесса заданий для запуска в указанные события или время.
- Hbase - это база данных без SQL, предоставляемая как часть Apache Hadoop.
- Spark - используется для выполнения обработки в памяти, которая выполняется намного быстрее, чем уменьшение карты Hadoop.
Поставщики Hadoop
Есть много компаний, предлагающих дистрибутивы Hadoop. Ниже приведены несколько лучших поставщиков Hadoop:
- Cloudera
- Hortonworks
- MapR
Есть несколько предварительных условий для изучения Hadoop. Предварительный опыт в Java и скриптовом языке необходим. Хотя Hadoop уже имеет свои собственные высокоуровневые языки программирования, такие как pig и hive, которые генерируют внутренний код для дальнейшей обработки, тем не менее, можно создать собственную программу сокращения карт для любого языка программирования, такого как Ruby, Python, Perl и даже Си.
Bigdata и Hadoop пользуются высоким спросом на современном рынке. Это увеличится еще больше в ближайшие дни. Многие организации уже переехали в Hadoop, а те, кто еще не собирается, скоро переедут. Существует текущий отчет о том, что крупные корпорации начали инвестировать в аналитику больших данных. Маркетинговый прогноз больших данных всегда находится в восходящем тренде и совсем не является недолговечным. Помимо всего этого, рабочие места в Hadoop и больших данных всегда предлагают высокую заработную плату по сравнению с другими технологиями.
Ведущие компании, занимающиеся большими данными и Hadoop
Ниже приведены несколько ведущих компаний, использующих наибольшее количество ресурсов Hadoop.
- Yahoo
- Амазонка
- Королевский банк Шотландии
- British Airways
- Expedia
- Walmart
Многие компании используют приложения для работы с большими данными. Эти:
-
Nokia
Для приложения используются компоненты Cloudera и Hadoop, такие как HDFS, HBase, Sqoop, Scribe. Он эффективно использовал данные пользователя, чтобы понять и улучшить пользовательский опыт. Он использует обработку данных и комплексный анализ для построения карты с прогнозируемыми моделями трафика и многоуровневой высоты.
-
ПАВ
Он сотрудничал с Hadoop, чтобы помочь ученым, занимающимся данными, получить лучшее понимание, предоставляя среду, которая дает визуальный и интерактивный опыт, помогая исследовать новые тенденции. Аналитические программы извлекают значимые данные из данных, а технология в памяти помогает ускорить доступ к данным.
Есть также много других компаний, использующих платформы больших данных для различного анализа. Это анализ данных о рейсах черного ящика в авиационной отрасли, разный анализ рынка акций и т. Д.
Преимущества Haddop
Ниже приведены некоторые из преимуществ Hadoop
- Масштабируемость - в отличие от традиционных СУБД, это платформа с высокой степенью масштабируемости, поскольку она может хранить большие наборы данных в распределенных кластерах на обычном оборудовании, работающем параллельно.
- Экономически эффективный - СУБД была слишком высока для хранения данных, которые были освобождены в Hadoop.
- Быстро и гибко - предлагает быстрый доступ к данным через распределенную файловую систему. Он также предлагает получить бизнес-представление из полуструктурированных и неструктурированных данных.
- Отказоустойчивость - всякий раз, когда какие-либо данные отправляются на узел, эти же данные копируются на другие узлы, к которым можно получить доступ в случае любого отказа первого узла.
Вывод - что такое Big Data и Hadoop
Данные постоянно растут, и, следовательно, всегда нужны большие данные и Hadoop, чтобы разобраться в этих данных. По этой причине профессионалы с навыками Hadoop всегда найдут широкие возможности в ближайшие дни и могут стать жизненно важным активом для организации, стимулирующей бизнес и карьеру.
Рекомендуемые статьи
Это было руководство о том, что такое Big Data и Hadoop. Здесь мы обсудили основные понятия и компоненты больших данных и Hadoop. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Примеры аналитики больших данных
- Использование Hadoop
- Руководство по визуализации данных
- Что такое аналитика больших данных?