
Разница между Hive и HBase
Apache Hive и HBase - это технологии больших данных на основе Hadoop. Они оба использовали для запроса данных. Hive и HBase работают поверх Hadoop и отличаются по своим функциональным возможностям. Hive - это диалект SQL, основанный на уменьшении карты, тогда как HBase поддерживает только MapReduce. HBase хранит данные в форме пар ключ / значение или семейства столбцов, тогда как Hive не хранит данные.
Личные различия между Hive и HBase (Инфографика)
Ниже приведено 8 лучших отличий между Hive и HBase
Ключевые различия между Hive и HBase
- Hbase совместим с кислотой, а Hive - нет.
- Hive поддерживает критерии разбиения и фильтрации на основе формата даты, тогда как HBase поддерживает автоматическое разбиение.
- Hive не поддерживает операторы обновления, тогда как HBase поддерживает их.
- Hbase быстрее по сравнению с Hive при получении данных.
- Hive используется для обработки структурированных данных, тогда как HBase, поскольку он не содержит схем, может обрабатывать данные любого типа.
- Hbase обладает высокой (горизонтальной) масштабируемостью по сравнению с Hive.
- Hive анализирует данные в HDFS с поддержкой SQL-запросов, а затем преобразует их в карту и сокращает количество заданий, тогда как в Hbase, поскольку потоковая передача выполняется в режиме реального времени, он непосредственно выполняет свои операции с базой данных, разбивая таблицы и семейства столбцов.
- когда мы обращаемся к запросам данных, куст использует оболочку, известную как оболочка Hive, для выдачи команд, тогда как HBase, поскольку это база данных, мы будем использовать команду для обработки данных в HBase.
- Чтобы перейти к оболочке Hive, мы будем использовать команду hive. После этого он будет выглядеть как куст>. В HBase мы просто указываем как Use HBase.
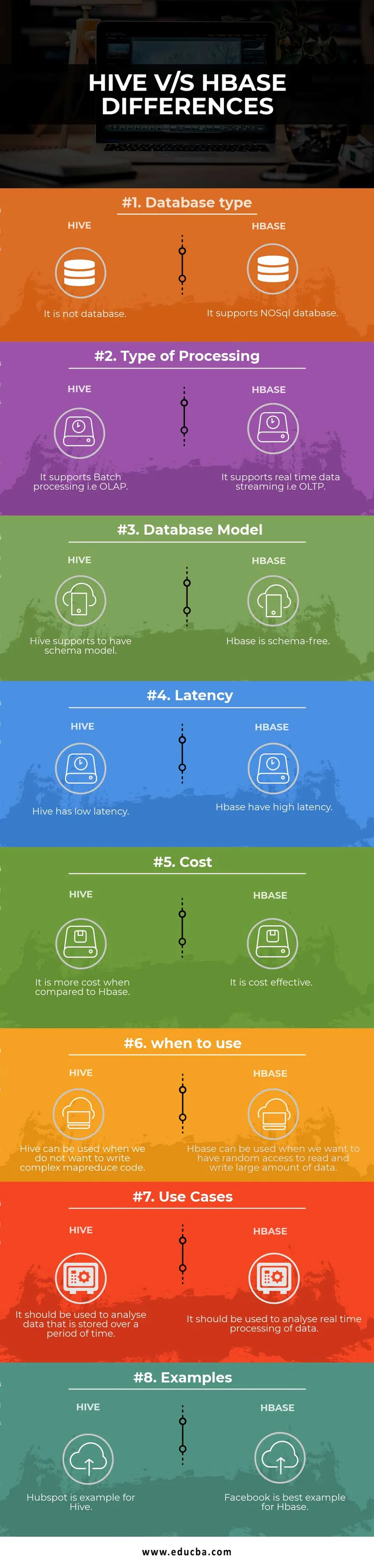
Hive vs HBase Сравнительная таблица
| Основа для сравнения | улей | Hbase |
| Тип базы данных | Это не база данных | Поддерживает базу данных NoSQL |
| Тип обработки | Поддерживает пакетную обработку т.е. OLAP | Он поддерживает потоковую передачу данных в реальном времени, т. Е. OLTP |
| Модель базы данных | Улей поддерживает модель схемы | Hbase не содержит схем |
| Задержка | Улей имеет низкую задержку | Hbase имеет высокую задержку |
| Стоимость | Это дороже по сравнению с HBase | Это экономически эффективно |
| когда использовать | Hive можно использовать, когда мы не хотим писать сложный код MapReduce | HBase может использоваться, когда мы хотим иметь произвольный доступ для чтения и записи большого количества данных |
| Случаи использования | Он должен использоваться для анализа данных, которые хранятся в течение определенного периода времени | Его следует использовать для анализа обработки данных в режиме реального времени. |
| Примеры | Hubspot является примером для Hive | Facebook - лучший пример для Hbase |
Различия в кодировании между Hive и HBase
Давайте теперь обсудим основные различия между Hive и HBase в кодировании.
| Основа для сравнения | улей | Hbase |
| Создать базу данных | СОЗДАТЬ БАЗУ ДАННЫХ (ЕСЛИ НЕ СУЩЕСТВУЕТ) ИМЯ БАЗЫ ДАННЫХ; | Поскольку Hbase является базой данных, нам не нужно создавать конкретную базу данных |
| Чтобы удалить базу данных | DROP DATABASE (ЕСЛИ СУЩЕСТВУЕТ) ИМЯ БАЗЫ ДАННЫХ (ОГРАНИЧЕНИЕ ИЛИ КАСКАД); | Не Доступно |
| Создать таблицу | СОЗДАТЬ (ВРЕМЕННЫЙ ИЛИ ВНЕШНИЙ) СТОЛ (ЕСЛИ НЕ СУЩЕСТВУЕТ) НАИМЕНОВАНИЕ ТАБЛИЦЫ ((имя-столбца data_type (комментарий столбца-комментария), ….)) (комментарий table_comment) (формат строки ROW FORMAT) (сохраняется как формат файла) | СОЗДАЙТЕ '', '' |
| Изменить таблицу | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) столбец-имя ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name CHANGE имя-столбца new-name new-type ALTER TABLE name ЗАМЕНИТЕ КОЛОННЫ (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Отключение таблицы | Не Доступно | отключить 'TABLE-NAME' -> чтобы отключить указанное имя таблицы
disable_all 'r *' -> чтобы отключить все таблицы, которые соответствуют регулярному выражению |
| Включение таблицы | Не Доступно | включить 'TABLE-NAME' |
| Бросить стол | DROP TABLE ЕСЛИ СУЩЕСТВУЕТ table-name | Если мы хотим удалить таблицу, то сначала нужно отключить ее
отключить «имя таблицы» сбросьте имя таблицы Точно так же мы можем использовать disable_all и drop_all, чтобы удалить таблицы, которые соответствуют указанному регулярному выражению. |
| К списку баз данных | показывать базы данных; | Не Доступно |
| Чтобы отобразить таблицы в базе данных | показывать таблицы; | список |
| Описать схему таблицы | описать имя таблицы; | опишите «имя таблицы» |
Интеграция Hive против HBase
- Установите и настройте Hive.
- Установите и настройте HBase.
- Для интеграции Hive и HBase мы используем HANDLERS STORAGE в Hive.
- Обработчики хранилища - это комбинация SERDE, InputFormat, OutputFormat, которая принимает любую внешнюю сущность в виде таблицы в Hive.
- Таким образом, эта функция помогает пользователю выполнять запросы SQL, независимо от того, присутствует ли таблица в Hadoop или в базе данных на основе NOSQL, такой как HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Теперь рассмотрим один пример подключения Hive к HBase с использованием HiveStorageHandler:
- Сначала нам нужно создать таблицу Hbase с помощью команды.
создать 'Student', 'personalinfo', 'отдел информации'
-> Personalinfo и dept info создают две разные семейства столбцов в таблице Student.
- Нам нужно вставить некоторые данные в таблицу Student. Например, как упомянуто ниже.
положить 'student', 'sid01 ′, ' personalinfo: name ', ' Ram '
положить 'student', 'sid01 ′, ' personalinfo: mailid ', ' '
положить 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
put 'Student', 'sid01', 'deptinfo: joinyear', '1994 ′
-> Точно так же мы можем создать данные для sid02, sid03…
- Теперь нам нужно создать таблицу Hive, указывающую на таблицу HBase.
- Для каждого столбца в Hbase мы создадим одну конкретную таблицу для этого столбца в Hive. В этом случае мы создадим 2 таблицы в Hive.
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Точно так же, нам нужно создать таблицу сведений об отделе в улье.
- Теперь мы можем написать SQL-запрос в улье, как указано ниже.
select * from student_hbase;
Таким образом, мы можем интегрировать Hive с HBase.
Вывод - Hive vs HBase
Как уже говорилось, обе они представляют собой разные технологии, которые обеспечивают разные функциональные возможности, в которых Hive работает с использованием языка SQL, и его также можно назвать HQL и HBase, использующим пары ключ-значение для анализа данных. Hive и HBase работают лучше, если их объединять, поскольку Hive имеет низкую задержку и может обрабатывать огромное количество данных, но не может поддерживать актуальные данные, а HBase не поддерживает анализ данных, но поддерживает обновления на уровне строк в большом количестве. данных.
Рекомендуемая статья
Это было руководство по Hive vs HBase, их значению, сравнению лицом к лицу, ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Apache Pig против Apache Hive - Лучшие 12 полезных отличий
- Узнайте 7 лучших различий между Hadoop и HBase
- 12 лучших сравнений Apache Hive и Apache HBase (Инфографика)
- Hadoop vs Hive - узнай лучшие отличия