
Что такое алгоритм SVM?
SVM расшифровывается как опорная векторная машина. SVM - это контролируемый алгоритм машинного обучения, который обычно используется для задач классификации и регрессии. Распространенными применениями алгоритма SVM являются система обнаружения вторжений, распознавание почерка, предсказание структуры белка, обнаружение стеганографии в цифровых изображениях и т. Д.
В алгоритме SVM каждая точка представляется как элемент данных в n-мерном пространстве, где значение каждого объекта является значением конкретной координаты.
После построения графика была проведена классификация путем нахождения гиперплоскости, которая различает два класса. Обратитесь к изображению ниже, чтобы понять эту концепцию.
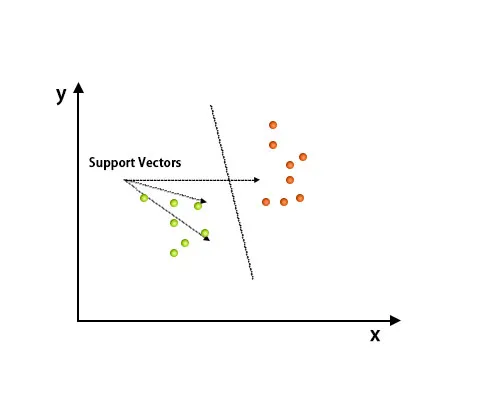
Алгоритм опорных векторов в основном используется для решения задач классификации. Поддерживающие векторы - это не что иное, как координаты каждого элемента данных. Машина опорных векторов - это граница, которая различает два класса с использованием гиперплоскости.
Как работает алгоритм SVM?
В приведенном выше разделе мы обсудили дифференцирование двух классов с использованием гиперплоскости. Теперь посмотрим, как работает этот алгоритм SVM.
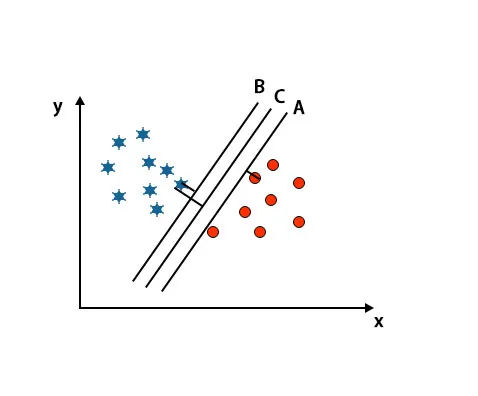
Сценарий 1: определить правильную гиперплоскость
Здесь мы взяли три гиперплоскости, то есть A, B и C. Теперь мы должны определить правильную гиперплоскость, чтобы классифицировать звезду и окружность.
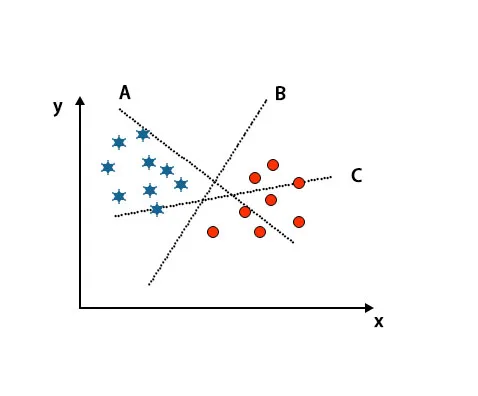
Чтобы определить правильную гиперплоскость, мы должны знать правило большого пальца. Выберите гиперплоскость, которая различает два класса. На вышеупомянутом изображении гиперплоскость B очень хорошо различает два класса.
Сценарий 2: Определите правильную гиперплоскость
Здесь мы взяли три гиперплоскости, т. Е. A, B и C. Эти три гиперплоскости уже очень хорошо дифференцируют классы.
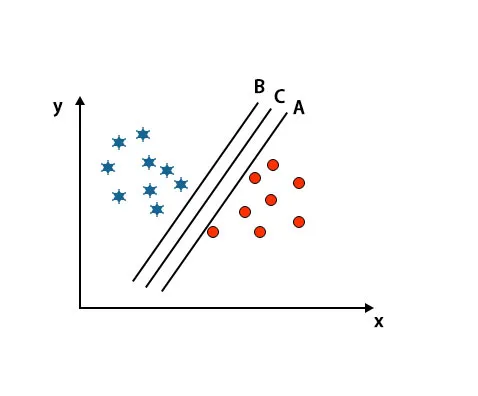
В этом сценарии для определения правильной гиперплоскости мы увеличиваем расстояние между ближайшими точками данных. Это расстояние не что иное, как запас. Смотрите изображение ниже.
На вышеупомянутом изображении граница гиперплоскости C выше, чем гиперплоскости A и гиперплоскости B. Таким образом, в этом сценарии C является правой гиперплоскостью. Если мы выберем гиперплоскость с минимальным запасом, это может привести к неправильной классификации. Поэтому мы выбрали гиперплоскость C с максимальным запасом из-за надежности.
Сценарий 3: Определите правильную гиперплоскость
Примечание. Для идентификации гиперплоскости следуйте тем же правилам, что и в предыдущих разделах.
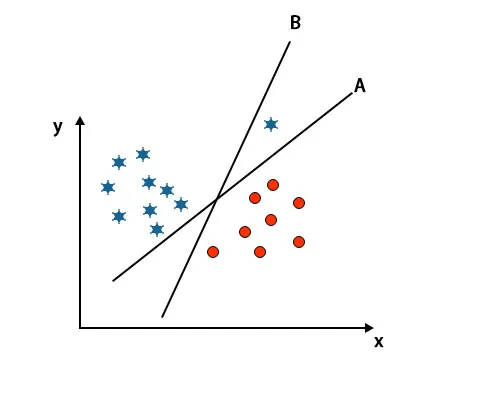
Как вы можете видеть на вышеупомянутом изображении, край гиперплоскости B больше, чем край гиперплоскости A, поэтому некоторые выберут гиперплоскость B вправо. Но в алгоритме SVM он выбирает ту гиперплоскость, которая классифицирует классы с точностью до максимизации запаса. В этом сценарии гиперплоскость A классифицировала все точно, и есть некоторая ошибка с классификацией гиперплоскости B. Следовательно, A - правильная гиперплоскость.
Сценарий 4: классифицировать два класса
Как вы можете видеть на приведенном ниже изображении, мы не можем дифференцировать два класса, используя прямую линию, потому что одна звезда лежит как выброс в другом классе круга.
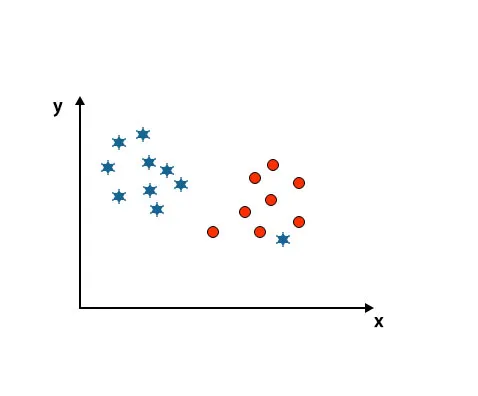
Здесь одна звезда в другом классе. Для звездного класса эта звезда является выбросом. Из-за свойства робастности алгоритма SVM он найдет правильную гиперплоскость с более высоким запасом, игнорирующую выброс.
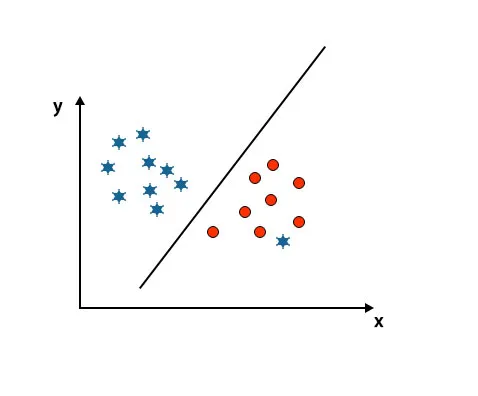
Сценарий 5: Тонкая гиперплоскость для дифференциации классов
До сих пор мы смотрели линейную гиперплоскость. На изображении ниже мы не имеем линейной гиперплоскости между классами.
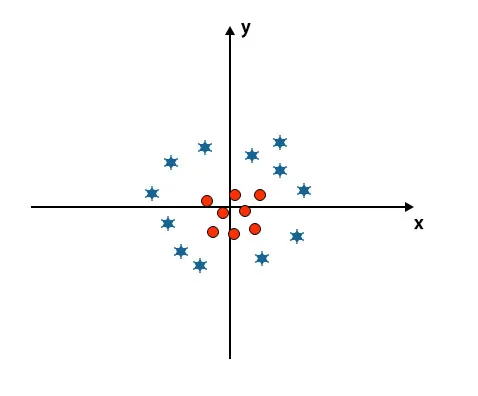
Чтобы классифицировать эти классы, SVM вводит некоторые дополнительные функции. В этом сценарии мы собираемся использовать эту новую функцию z = x 2 + y 2.
Отображает все точки данных на осях X и Z.

Заметка
- Все значения на оси z должны быть положительными, потому что z равно сумме х в квадрате и у в квадрате.
- На вышеупомянутом графике красные круги закрыты относительно начала оси x и оси y, приводя значение z к более низкому значению, и звезда точно противоположна окружности, это далеко от начала оси x и ось Y, ведущая значение z к высокой.
В алгоритме SVM легко классифицировать, используя линейную гиперплоскость между двумя классами. Но возникает вопрос: нужно ли добавить эту особенность SVM для идентификации гиперплоскости. Таким образом, ответ - нет, для решения этой проблемы в SVM есть методика, известная как трюк ядра.
Уловка ядра - это функция, которая преобразует данные в подходящую форму. Существуют различные типы функций ядра, используемых в алгоритме SVM: полиномиальная, линейная, нелинейная, радиальная базисная функция и т. Д. Здесь с использованием трюка ядра низкоразмерное входное пространство преобразуется в многомерное пространство.
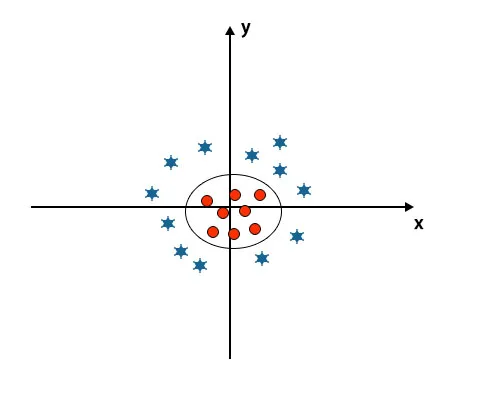
Когда мы смотрим на гиперплоскость начала оси и оси y, она выглядит как круг. Смотрите изображение ниже.
Плюсы алгоритма SVM
- Даже если входные данные являются нелинейными и неразделимыми, SVM генерируют точные результаты классификации благодаря своей надежности.
- В функции принятия решения он использует подмножество обучающих точек, называемых опорными векторами, следовательно, оно эффективно использует память.
- Полезно решить любую сложную проблему с помощью подходящей функции ядра.
- На практике модели SVM обобщены с меньшим риском переоснащения в SVM.
- SVM отлично подходит для классификации текста и при поиске лучшего линейного разделителя.
Минусы алгоритма SVM
- Это занимает много времени обучения при работе с большими наборами данных.
- Трудно понять окончательную модель и индивидуальное воздействие.
Вывод
Он руководствовался алгоритмом поддержки векторной машины, который является алгоритмом машинного обучения. В этой статье мы подробно обсудили, что такое алгоритм SVM, как он работает и каковы его преимущества.
Рекомендуемые статьи
Это было руководство по алгоритму SVM. Здесь мы обсудим его работу со сценарием, плюсами и минусами алгоритма SVM. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Алгоритмы интеллектуального анализа данных
- Методы добычи данных
- Что такое машинное обучение?
- Инструменты машинного обучения
- Примеры алгоритма C ++