

Введение в Python DataFrame Pandas
Несколько расширений для библиотеки Python, Pandas, можно найти в Интернете. Одним из таких является панель (панорамирование) данных (дас). Это слово * Panel * тонко намекает на двухмерную структуру данных, присутствующую в этой библиотеке, что значительно расширяет возможности ее пользователей. Эта структура называется DataFrame.
По сути, это матрица строк и столбцов, содержащая весь ваш набор данных, с очень сложными вариантами индексации. DataFrame (DF) можно представить в виде картинки, очень похожей на таблицу Excel. Но что делает его мощным, так это легкость, с которой аналитические и трансформационные операции могут выполняться с данными, хранящимися в DataFrame.
Что такое дата-фрейм Python Pandas?
Страница Pydata может быть передана для чего-то официального определения.
При правильном понимании он упоминает DataFrame как столбчатую структуру, способную хранить любой объект python (включая сам DataFrame) как одно значение ячейки. (Ячейка индексируется с использованием уникальной комбинации строк и столбцов)
DataFrames состоит из трех основных компонентов: данных, строк и столбцов.
- Данные: это относится к фактическим объектам / объектам, хранящимся в ячейке в DataFrame, и значениям, представленным этими объектами. Объект имеет любой допустимый тип данных Python, встроенный или определенный пользователем.
- Строки: Ссылки, используемые для идентификации (или индексации) определенного набора наблюдений из полных данных, хранящихся в DataFrame, называются Строкой. Просто чтобы прояснить это, он представляет используемые индексы, а не только данные в конкретном наблюдении.
- Столбцы. Ссылки, используемые для идентификации (или индексации) набора атрибутов для всех наблюдений в DataFrame. Как и в случае строк, они относятся к индексу столбца (или заголовкам столбца), а не только к данным в столбце.
Итак, без лишних слов, давайте попробуем несколько способов создания этих удивительно мощных структур.
Шаги по созданию фреймов данных Python Pandas
DataFrame Python Pandas может быть создан с использованием следующей реализации кода,
1. Импорт панд
Для создания DataFrames необходимо импортировать библиотеку панд (здесь нет ничего удивительного). Мы импортируем его с псевдонимом pd, чтобы удобно ссылаться на объекты в модуле.
Код:
import pandas as pd
2. Создание первого объекта DataFrame
После импорта библиотеки все методы, функции и конструкторы становятся доступными в вашей рабочей области. Итак, давайте попробуем создать ванильный DataFrame.
Код:
import pandas as pd
df = pd.DataFrame()
print(df)
Выход:
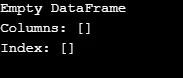
Как показано в выходных данных, конструктор возвращает пустой DataFrame.
Теперь давайте сосредоточимся на создании DataFrames из данных, хранящихся в некоторых вероятных представлениях.
- Фрейм данных из словаря. Допустим, у нас есть словарь, в котором хранится список компаний в Software Domain и количество лет, в течение которых они были активны.
Код:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Давайте посмотрим представление возвращенного объекта DataFrame, напечатав его на консоли.
Выход:

Как видно, каждый ключ словаря обрабатывается как столбец в DataFrame, и индексы строк генерируются автоматически, начиная с 0. Довольно просто, да!
Теперь предположим, что вы хотите присвоить ему пользовательский индекс вместо 0, 1, .. 4. Вам просто нужно передать нужный список в качестве параметра конструктору, и pandas сделает все необходимое.
Код:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Выход:
Возраст компании
Альфа Google 21
Бета Амазонка 23
Гамма Инфосис 38
Delta Directi 22
Теперь вы можете установить индексы строк на любое желаемое значение.
- DataFrame из файла CSV: Давайте создадим файл CSV, содержащий те же данные, что и в случае нашего словаря. Давайте назовем файл CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Файл может быть загружен в фрейм данных (при условии, что он присутствует в текущем рабочем каталоге) следующим образом.
Код:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Выход:
Возраст компании
0 Google 21
1 амазонка 23
2 Infosys 38
3 Directi 22
Задание имен параметров в обход списка значений присваивает им заголовки столбцов в том же порядке, в котором они присутствуют в списке. Аналогично, индексы строк можно установить, передав список параметру index, как показано в предыдущем разделе. Заголовок = Нет указывает на отсутствие заголовков столбцов в файле данных.
Теперь предположим, что имена столбцов были частью файла данных. Тогда установка header = False сделает необходимую работу.
3. CompanyAgeWithHeader.csv
Компания, Возраст
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Код изменится на
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Выход:
Возраст компании
0 Google 21
1 амазонка 23
2 Infosys 38
3 Directi 22
- DataFrame из файла Excel: данные часто передаются в файлы Excel, поскольку они остаются наиболее популярным инструментом, используемым обычными людьми для отслеживания Adhoc. Таким образом, это не должно игнорироваться нашим обсуждением.
Предположим, что данные, такие же, как в CompanyAgeWithHeader.csv, теперь хранятся в CompanyAgeWithHeader.xlsx на листе с именем Company Age. Тот же самый DataFrame, что и выше, будет создан с помощью следующего кода.
Код:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Выход:
Возраст компании
0 Google 21
1 амазонка 23
2 Infosys 38
3 Directi 22
Как вы можете видеть, тот же самый DataFrame может быть создан путем передачи имени файла и имени листа.
Дальнейшее чтение и дальнейшие шаги
Показанные методы составляют очень маленькое подмножество по сравнению со всеми различными способами создания DataFrames. Они были созданы с намерением начать. Вы должны обязательно изучить перечисленные ссылки и попытаться изучить другие способы, в том числе подключение к базе данных для чтения данных непосредственно в DataFrame.
Вывод
Pandas DataFrame зарекомендовал себя как новатор в мире науки о данных и аналитики данных, а также удобен для специальных краткосрочных проектов. Он поставляется с целым рядом инструментов, способных с легкостью нарезать и нарезать кубики набора данных. Надеюсь, это послужит трамплином в вашем будущем путешествии.
Рекомендуемые статьи
Это руководство по Python-Pandas DataFrame. Здесь мы обсуждаем шаги по созданию фрейма данных python-pandas вместе с его реализацией кода. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- 15 главных особенностей Python
- Различные типы наборов Python
- Лучшие 4 типа переменных в Python
- 6 лучших редакторов Python
- Массивы в структуре данных