
Введение в конвейер данных AWS
Данные растут в геометрической прогрессии день ото дня и становятся сложными для управления по сравнению с прошлым. Нам нужны инструменты и сервисы для эффективного управления нашими данными и при меньших затратах, и именно здесь на ум приходит AWS Data Pipeline. Речь идет не просто о хранении данных, но о том, что вам нужно анализировать, обрабатывать, преобразовывать данные в нужную форму в одном месте, всего этого можно достичь с помощью AWS Data Pipeline.
Потребность в конвейере данных
Давайте попробуем понять необходимость конвейера данных на примере:
Пример № 1
У нас есть веб-сайт, который отображает изображения и картинки на основе поисковых запросов или фильтров. Наше основное внимание уделяется подаче контента. Есть определенные цели для достижения этого:
- Улучшение доставки контента. Эффективное и быстрое удовлетворение потребностей пользователей.
- Эффективное управление приложением: хранение пользовательских данных, а также журналов веб-сайта для последующих аналитических целей.
- Улучшение бизнеса. Использование хранимых данных и аналитики позволяет принять решение о том, чтобы сделать бизнес лучше и дешевле.
Пример № 2
Есть определенные узкие места, о которых нужно позаботиться для достижения целей:
- Огромный объем данных в разных форматах и в разных местах, что делает обработку, хранение и миграцию данных сложной задачей.
Различные компоненты хранения данных для разных типов данных:
- Возможные данные в реальном времени для зарегистрированных пользователей: DB Dynamo .
- Логи веб-сервера для потенциальных пользователей: Amazon S3 .
- Демографические данные и учетные данные для входа в систему: Amazon RDS.
- Данные датчика и набор данных сторонних производителей: Amazon S3.
Решения
- Возможное решение: мы видим, что нам приходится иметь дело с различными типами инструментов для преобразования данных из неструктурированных в структурированные для анализа. Здесь мы должны использовать различные инструменты для хранения данных и снова для преобразования, анализа и хранения обработанных данных. Не рентабельное решение.
- Оптимальное решение: используйте конвейер данных, который обрабатывает, визуализирует и переносит. Конвейер данных может быть полезен для переноса данных из разных мест, а также для анализа данных и обработки в одном месте от вашего имени.
Что такое конвейер данных AWS?
AWS Data Pipeline - это в основном веб-сервис, предлагаемый Amazon, который помогает вам преобразовывать, обрабатывать и анализировать ваши данные масштабируемым и надежным способом, а также хранить обработанные данные в S3, DynamoDb или вашей локальной базе данных.
- С AWS Data Pipeline вы можете легко получить доступ к данным из разных источников.
- Преобразование и обработка этих данных в масштабе.
- Эффективно переносите результаты в другие службы, такие как S3, таблица DynamoDb или локальное хранилище данных.
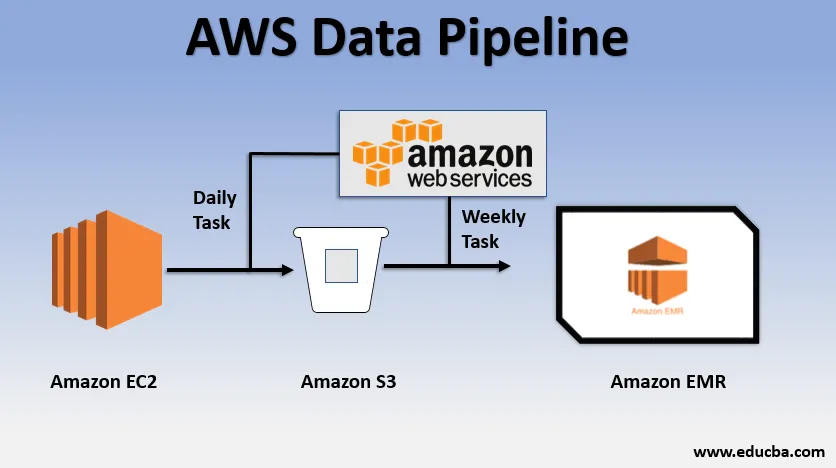
Пример базового использования конвейера данных
- Мы могли бы иметь веб-сайт, развернутый поверх EC2, который генерирует журналы каждый день.
- Простая ежедневная задача может быть скопирована из E2 и доставить ее в корзину S3.
- Еженедельной задачей может быть обработка данных и запуск анализа данных через Amazon EMR для создания еженедельных отчетов на основе всех собранных данных.
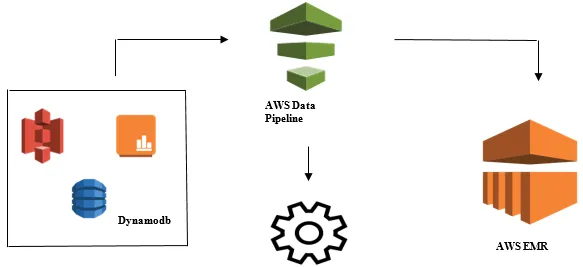
Запуск анализа данных с помощью AWS Data Pipeline
- Сбор данных из разных источников данных, таких как - S3, Dynamodb, Local, данные датчиков и т. Д.
- Выполнение преобразования, обработки и анализа в AWS EMR для создания еженедельных отчетов.
- Еженедельный отчет сохраняется в Redshift, S3 или локальной базе данных.
Преимущества AWS Data Pipeline
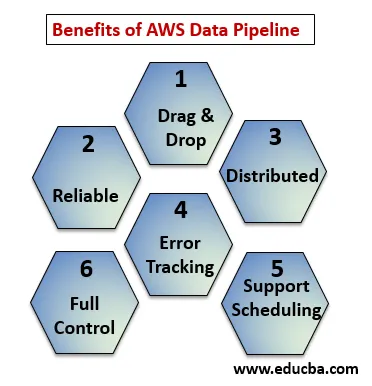
Ниже приведены пояснения преимуществ AWS Data Pipeline:
- Перетащите консоль, которая проста для понимания и использования.
- Распределенная и надежная инфраструктура: конвейеры данных работают в масштабируемых службах и являются надежными в случае сбоя какой-либо ошибки или задачи, ее можно настроить на повторную попытку.
- Поддерживает планирование и отслеживание ошибок: вы можете планировать свои задачи и отслеживать, что получилось неудачно и успешно.
- Распределенный: Может работать параллельно на нескольких машинах или линейно.
- Полный контроль над вычислительными ресурсами, такими как EC2, кластеры EMR.
Компоненты конвейера данных AWS
Ниже приведены компоненты конвейера данных AWS:
1. Определение трубопровода
Преобразуйте свою бизнес-логику в конвейер данных AWS.
- Узлы данных : содержит имя, местоположение, формат источника данных (S3, DynamodB, локальный)
- Действия : перемещать, преобразовывать или выполнять запросы к вашим данным.
- Расписание : график ваших ежедневных или еженедельных мероприятий.
- Предварительное условие : Условия, такие как запуск планировщика, проверяют наличие данных в источнике.
- Ресурсы : Вычислить ресурсы EC2, EMR.
- Действия : Обновление о конвейере данных, отправка уведомлений, триггер тревоги.
2. Трубопроводы
Здесь вы планируете и запускаете задачи для выполнения определенных действий.
- Компоненты конвейера C : Компоненты конвейера такие же, как компоненты определения конвейера.
- Экземпляры. Во время выполнения задач AWS компилирует все компоненты для создания определенных экземпляров, которые можно выполнить. Такие экземпляры имеют всю информацию о конкретных задачах.
- Попытки: мы уже обсуждали, насколько надежен конвейер данных с его механизмами повтора. Здесь вы указываете, сколько раз вы хотите повторить задачу в случае ее сбоя.
3. Задача Runner
Запрашивает или опрашивает задачи из AWS Data Pipeline, а затем выполняет эти задачи.
Цены на конвейер данных AWS
Ниже приведены пояснения цен для конвейера данных AWS:
1. Бесплатный уровень
Вы можете начать работу с AWS Data Pipeline бесплатно как часть уровня бесплатного использования AWS. Новые подписчики получают каждый месяц некоторые бесплатные льготы на один год:
- 3 Предварительные условия низкочастотной работы на AWS без какой-либо оплаты.
- 5 Работа с низкой частотой на AWS без какой-либо оплаты.
2. Низкочастотный
Низкая частота предназначена для работы один раз в день или меньше. Конвейер данных использует ту же стратегию выставления счетов, что и другие веб-сервисы AWS, т. Е. Оплачивается за использование. Оплачивается счет того, как часто ваши задачи, действия и предварительные условия выполняются каждый день и где они выполняются (AWS или локально). Высокочастотные мероприятия планируется проводить чаще, чем раз в день.
Пример: мы можем запланировать выполнение операции каждый час и обрабатывать журналы веб-сайта или каждые 12 часов. Принимая во внимание, что низкочастотные действия - это те, которые выполняются один раз в день или реже, если предварительные условия не выполняются. Неактивные трубопроводы имеют состояния НЕАКТИВНО, ОЖИДАЮТ и ЗАКОНЧЕНЫ.
3. Цены на конвейер данных AWS показаны в зависимости от региона.
Регион № 1: Восток США (Северная Вирджиния), Запад США (Орегон), Азиатско-Тихоокеанский регион (Сидней), ЕС (Ирландия)
| Высокая частота | Низкая частота | |
| Действия или предварительные условия, выполняемые через AWS | 1 доллар США в месяц | 0, 06 доллара в месяц |
| Действия или предварительные условия, выполняемые локально | $ 2, 50 в месяц | $ 1, 50 в месяц |
| Неактивные трубопроводы: $ 1, 00 в месяц |
Регион № 2: Азиатско-Тихоокеанский регион (Токио)
| Высокая частота | Низкая частота | |
| Действия или предварительные условия, выполняемые через AWS | $ 0, 9524 в месяц | $ 0, 5715 в месяц |
| Действия или предварительные условия, выполняемые локально | $ 2.381 в месяц | $ 1, 4286 в месяц |
| Неактивные трубопроводы: $ 0, 9524 в месяц |
Трубопровод, в котором ежедневная работа, то есть низкочастотная операция на AWS по переносу данных из таблицы DynamoDB в Amazon S3, будет стоить $ 0, 60 в месяц. Если мы добавим EC2 для создания отчета на основе данных Amazon S3, общая стоимость конвейера составит 1, 20 доллара в месяц. Если мы будем выполнять это действие каждые 6 часов, это будет стоить 2 доллара в месяц, потому что тогда это будет высокочастотное мероприятие.
Вывод
AWS Data Pipeline - очень удобное решение для экспоненциально растущего объема данных при меньших затратах. Он очень надежный и масштабируемый в зависимости от вашего использования. AWS Data Pipeline - это отличный выбор для достижения всех наших бизнес-целей, когда речь идет о любых бизнес-задачах, связанных с большим объемом данных.
Рекомендуемые статьи
Это руководство по конвейеру данных AWS. Здесь мы обсудим потребности конвейера данных, что такое конвейер данных AWS, его компоненты и детали ценообразования. Вы также можете просмотреть другие наши статьи, чтобы узнать больше -
- AWS EBS
- Базы данных AWS
- Что такое AWS EC2?
- Преимущества визуализации данных
- 7 лучших конкурентов AWS с возможностями
- Изучите список функций веб-сервисов Amazon