

Что такое функция улья?
Как мы знаем сегодня, Hadoop является одной из универсальных технологий в области больших данных. Hadoop обладает способностью справляться с большим набором данных, но, поскольку рост данных является пропорциональным, написание программ сокращения карт становится трудным. Для выполнения SQL-запросов, представленных в HDFS, одна из таких технологий была представлена Hadoop под названием apache Hive, запущенная Facebook. Hive высоко используется аналитиком данных. Они развернуты для трех функций, а именно: суммирование данных, анализ данных в распределенном файле и запрос данных. Hive предоставляет SQL-подобные запросы, называемые HQL - язык высоких запросов поддерживает пользовательские функции DML. Компилятор Hive внутренне преобразует этот запрос в задания сокращения карт, что упрощает работу Hadoop при написании сложных программ. Мы могли бы найти куст в таких приложениях, как хранилище данных, визуализация данных и специальный анализ, Google Analytics. Основное преимущество заключается в том, что они используют знания SQL, которые являются базовыми навыками, реализованными среди исследователей данных и специалистов по программному обеспечению.
Различные функции улья в деталях
Hive поддерживает разные типы данных, которых нет в других системах баз данных. он включает в себя карту, массив и структуру. Hive имеет несколько встроенных функций для выполнения нескольких математических и арифметических функций специального назначения. Функции в улье можно разделить на следующие типы. Это встроенные функции и пользовательские функции.
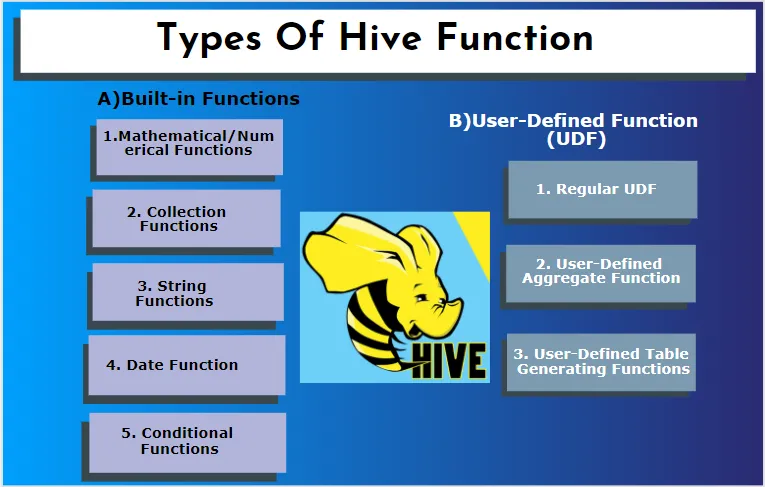
А) Встроенные функции
Эти функции извлекают данные из таблиц улья и обрабатывают вычисления. Некоторые из встроенных функций:
1. Математические / Числовые Функции
Эти функции в основном используются для математических расчетов. Эти функции используются в запросах SQL.
| Имя функции | пример | Описание |
| ABS (двойной х) | Hive> выберите ABS (-200) из tmp; | Он вернет абсолютное значение числа. |
| CEIL (двойной х) | Hive> выберите CEIL (8.5) из tmp; | Он выберет наименьшее целое число, большее или равное значению x. |
| Рэнд (), Рэнд (int seed) | Hive> выберите Rand () из tmp;
Рэнд (0-9) | Возвращает случайное число, в зависимости от начального значения генерируемые случайные числа будут детерминированными. |
| Пау (двойной х, двойной у) | Hive> выберите Pow (5, 2) из tmp; | Возвращает значение x, возведенное в степень y. |
| ЭТАЖ (двойной у) | Hive> выберите FLOOR (11.8) из tmp; | Возвращает максимальное целое число, которое меньше или равно значению y. |
| EXP (двойной) | Hive> выберите Exp (30) из tmp; | Он вернет значение экспоненты 30. Значения естественного алгоритма. |
| PMOD (int a, int b) | Hive> выберите PMOD (2, 4) из tmp; | Это дает положительный модуль числа. |
2. Коллекционные функции
Сброс всех элементов вместе и возврат отдельных элементов зависит от включенного типа данных.
| Имя функции | пример | Описание |
| Map_values (Карта) | Улей> выберите значения карты («привет», 45) | Он выбирает неупорядоченные элементы массива. |
| Размер (Карта) | Улей> выберите размер (карта) | Возвращает количество элементов в карте типов данных. |
| Array_contains (Массив b) | Hive> select array_contains (a (10)) | Возвращает TRUE, если массив содержит значение. |
| Sort_array (Array a) | Hive> select sort_array ((10, 3, 6, 1, 7)) | Сортирует входной массив в порядке возрастания в соответствии с естественным порядком элементов массива и возвращает значение. |
3. Строковые функции
С помощью строковых функций анализ данных выполнен превосходно.
| Разделить (строка s, строка погладить) | Hive> select split ('educba ~ hive ~ Hadoop, ' ~ ') вывод: ("educba", "hive", "Hadoop") | Он разбивает строку вокруг выражений pat и возвращает массив. |
| load (строка s, int Len, строка pad) | Улей> выберите нагрузку («EDUCBA», 6, «H») | Возвращает строки с правым отступом по длине строки. (персонаж персонажа). |
| Длина (строка строки) | Улей> выберите длину ('educba') | Эта функция возвращает длину строки. |
| Ртрим (строка а) | Hive> выберите rtrim («ТЕМА»);
Вывод: «Тема» | Возвращает результат путем обрезки пробелов с правого края. |
| Concat (строка m, строка n) | Hive> select concat ('data', 'ware') Результат: информационное обеспечение | В результате получается строка, объединяющая две строки, которая может принимать любое количество входных данных. |
| Обратный (строка s) | Улей> выберите реверс («Мобильный») | Возвращает результат обратной строки. |
4. Функция даты
Во избежание ошибки Null в выходных данных необходимо иметь формат данных в кусте. Необходимо иметь совместимость с датами, чтобы использовать функции даты, введенные в улье.
| Unix_timestamp ( строковая дата, строковый шаблон) | Hive> выберите Unix_ timestamp («2019-06-08», «гггг-мм-дд»); Результат: 124576 400 раз: 0, 146 секунды | Эта функция возвращает дату в определенный формат и возвращает секунды между датой и временем Unix. |
| Unix_timestamp ( строковая дата) | Hive> выберите Unix_ timestamp («2019-06-08 09:20:10», «гггг-мм-дд»); | Возвращает дату в формате «гггг-ММ-дд ЧЧ: мм: сс» в метку времени Unix. |
| Час (Строковая дата) | Улей> выберите час ('2019-06-08 09:20:10'); Результат: 09 часов | Возвращает час метки времени |
5. Условные функции
| If (логический тест, значение T истинно, t ложно) | Hive> выберите IF (1 = 1, «TRUE», «FALSE») как IF_CONDITION_TEST; | Он проверяет с условием, возвращает ли значение true 1, а false возвращает 0. |
| Не является нулевым (б) | Hive> Select не является нулевым (null); | Это извлекает не нулевые утверждения. если ноль возвращает ложь. |
| Объединение (значение 1, значение 2) | Пример: hive> select coalesce (Нуль, ноль, 4, ноль, 6). возвращается 4. | Сначала он выбирает ненулевые значения из списка значений. |
B) Пользовательская функция (UDF)
Hive использует пользовательские функции в соответствии с требованиями клиента, написанными в Java-программировании. Он реализован двумя интерфейсами: простым API и сложным API. Они вызываются из запроса улья. Три типа UDF:
1. Обычный UDF
Он работает на столе с одной строкой. Он создается путем создания класса java, а затем его упаковки в файл .jar, следующий шаг - проверка с помощью пути к классу улья. затем, наконец, выполняя их в запросе улья.
2. Определяемая пользователем агрегатная функция
Они используют агрегатные функции, такие как avg / mean, реализуя пять методов init (), iterate (), partal (), merge (), terminate ().
3. Определяемые пользователем функции генерации таблиц
Он работает с одной строкой в таблице и приводит к нескольким строкам.
Вывод
В заключение мы узнали, как работать с платформой улья со встроенными функциями и пользовательскими функциями подробно из этой статьи. В большинстве организаций есть программист и разработчик SQL для работы на стороне сервера, но улей apache - это мощный инструмент, который помогает им использовать инфраструктуру Hadoop без каких-либо предварительных знаний о программах и сокращении карт. Hive помогает новым пользователям начать анализировать данные без каких-либо препятствий.
Рекомендуемые статьи
Это руководство по функции улья. Здесь мы обсуждаем концепцию, два разных типа функций и подфункций в Hive. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Лучшие строковые функции в улье
- Hive Интервью Вопросы
- Что такое RMAN Oracle?
- Что такое модель водопада?
- Введение в архитектуру улья
- Улей Заказать