
Введение в R CSV файлы
CSV-файлы широко используются для хранения информации в табличном формате, каждая строка является записью данных. Чтобы читать, записывать или манипулировать данными в R, у нас должны быть некоторые данные, доступные с нами. Данные могут быть найдены в Интернете или могут быть получены из различных источников, таких как опросы. С помощью R можно читать, записывать и редактировать данные, которые хранятся во внешней среде. R может читать и записывать данные из различных форматов, таких как XML, CSV и Excel. В этой статье мы увидим, как R можно использовать для чтения, записи и выполнения различных операций с файлами CSV.
Создание файла CSV в R
В этом разделе мы увидим, как можно создать и экспортировать фрейм данных в файл CSV в R. В первом мы создадим фрейм данных, который состоит из переменных employee и соответствующей зарплаты.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
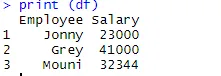
После создания фрейма данных пора использовать функцию экспорта R для создания CSV-файла в R. Чтобы экспортировать фрейм данных в CSV, мы можем использовать приведенный ниже код.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
В приведенной выше строке кода мы предоставили каталог путей для нашей славы данных и сохранили фрейм данных в формате CSV. В приведенном выше случае файл CSV был сохранен на моем персональном рабочем столе. Этот конкретный файл будет использоваться в нашем руководстве для выполнения нескольких операций.
Чтение файлов CSV в R
При выполнении аналитики с использованием R во многих случаях мы должны читать данные из файла CSV. R очень надежен при чтении файлов CSV. В приведенном выше примере мы создали файл, который будем использовать для чтения с помощью команды read.csv. Ниже приведен пример, чтобы сделать это в R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Приведенная выше команда читает файл Employee.csv, который доступен на рабочем столе, и отображает его в R studio. Команда заголовка подразумевает, что заголовок сделан доступным для набора данных, а команда sep подразумевает, что данные разделяются запятыми.
Запись файлов CSV в R
Запись в файл CSV - одна из самых полезных функций, доступных в R для аналитика данных. Это может быть использовано для записи отредактированного файла CSV в новый файл CSV для анализа данных. Команда write.csv используется для записи файла в CSV.
В приведенном ниже коде df во фрейме данных, в котором доступны наши данные, добавление используется для указания того, что новый файл создается вместо добавления или перезаписи в старом файле. Добавление false предполагает создание нового файла CSV. Sep представляет поле, разделенное запятой.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV Операции
Операции CSV необходимы для проверки данных после их загрузки в систему. R имеет несколько встроенных функций для проверки и проверки данных. Эти операции предоставляют полную информацию о наборе данных.
Одной из наиболее часто используемых команд является сводка.
> summary(df)
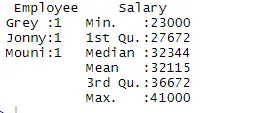
Сводная команда предоставляет нам статистику по столбцам. Числовая переменная описывается статистическим способом, который включает статистические результаты, такие как среднее, минимальное, медианное и максимальное. В приведенном выше примере, две переменные, которые являются Employee и Salary, разделены, и статистика для числовой переменной, которая является Salary, показана нам.
Команда View () используется для открытия набора данных в другой вкладке и проверки его вручную.
> View(df)

Функция Str предоставит пользователям более подробную информацию о столбце набора данных. В приведенном ниже примере мы видим, что переменная Employee имеет Factor в качестве типа данных, а переменная Salary имеет тип int (целое число) в качестве типа данных.
> str(df)

Во многих случаях нам нужно будет увидеть общее количество доступных строк в случае большого набора данных, для которого мы можем использовать команду nrow (). Пожалуйста, смотрите пример ниже.
> # to show the total number of rows in the dataset
> nrow(df)

Аналогичным образом, чтобы отобразить общее количество столбцов, мы можем использовать команду ncol ()
> ncol(df)

R позволяет нам отображать желаемое количество строк с помощью приведенной ниже команды. Когда их n строк доступно в наборе данных, мы можем указать диапазон отображаемых строк.
> # to display first 2 rows of the data
> df(1:2, )

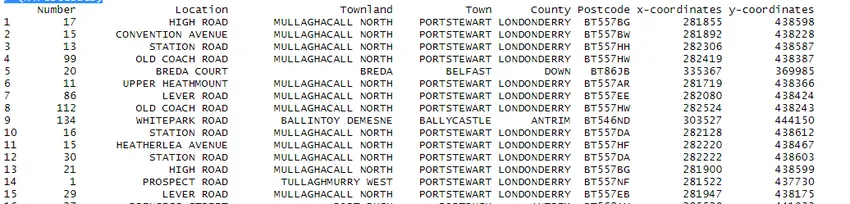
Операция с данными выполняется на большом наборе данных. Для иллюстрации я скачал набор данных с открытым исходным кодом NI из Интернета.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
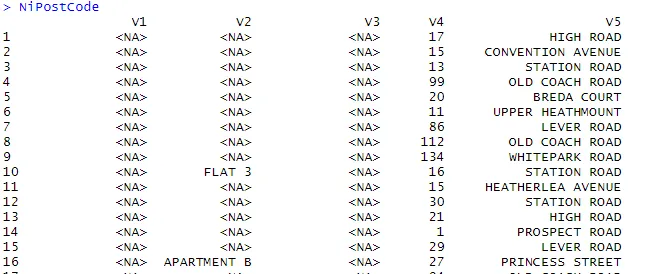
В приведенном выше наборе данных, мы видим, что имена заголовков отсутствуют и присутствует много нулевых значений. Набор данных необходимо очистить, чтобы подготовить его к анализу. На следующем шаге заголовки будут именоваться соответственно.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Теперь давайте посчитаем количество пропущенных значений в кадре данных и затем удалим их соответствующим образом.
> # count of all missing values
> table(is.na (NiPostCode))

Из приведенной выше команды видно, что общее количество пробелов или NA в кадре данных близко к 5445148. Удаление всех нулевых значений приведет к потере огромного количества данных, поэтому целесообразно удалить столбцы, в которых более половины 50% данных отсутствует.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Вывод
В этом уроке мы увидели, как CSV-файлы можно создавать, читать и добавлять с помощью операций в R. Мы узнали, как создать новый набор данных в R и затем импортировать его в формат CSV. Мы также видели несколько операций, таких как переименование заголовка и подсчет количества строк и столбцов.
Рекомендуемые статьи
Это руководство по R CSV Files. Здесь мы обсуждаем создание, чтение и запись файла CSV в R с помощью операций CSV. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- JSON против CSV
- Процесс добычи данных
- Карьера в Data Analytics
- Excel против CSV